
Pandasのcumsum()関数を使用すると、特定の軸の累積合計を計算できます。
累積合計とは、特定の時間における特定のデータセットの合計を指します。 これは、新しいデータが追加または削除されても、合計が変化し続けることを意味します。
Pandasでcumsum()関数を使用する方法について説明しましょう。
関数構文
関数の構文は次のとおりです。
|
1 |
DataFrame。cumsum((軸=なし、 スキップナ=真実、 *args、 ** kwargs)。 |
関数パラメーター
この関数は、次のパラメーターを受け入れます。
- 軸 –どの軸に沿って累積加算が実行されます。 デフォルトはゼロまたは列です。
- スキップナ –nullの行または列を許可または禁止します。
- ** kwargs –追加のキーワード引数。
関数の戻り値
この関数は、指定された軸に沿ったDataFrameの累積合計を返します。
例
以下の例は、Pandas DataFrameでcumsum()関数を使用する方法を示しています。
次のようなサンプルのDataFrameがあるとします。
|
1 |
#パンダをインポート |
列の累積合計を実行するには、次のようにします。
上記のコードは次のようになります。
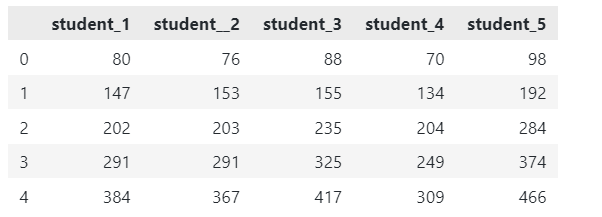
各列の値には、前の値の合計が含まれていることに注意してください。
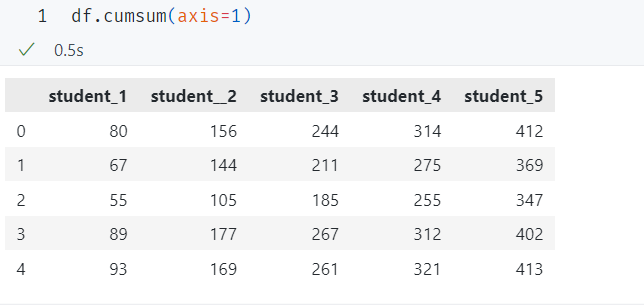
行を操作するには、軸を1つに設定します。 例は次のとおりです。
結論
この記事では、cumsum()関数を使用して、PandasDataFrameの特定の軸に対して累積合計を実行する方法について説明しました。
読んでくれてありがとう!!
The post パンダCumsum() appeared first on Gamingsym Japan.