
今回は、Pythonでマルチスレッド、マルチプロセスを利用するための方法を解説したいと思います。
最近のPCはマルチコアが当たり前になっていますが、何も考えずにプログラムを作ってしまうと1つのコアしか使ってくれません。
複数のコアで同時並行的に処理させたいのであれば、プログラムのそれなりの書き方が必要になってきます。
ただ、幸いなことにPythonでは非常に簡単にマルチスレッド、プロセスが利用できるので、CPUパワーを使って処理速度を速くしたい方は、是非今回の記事をご一読下さい。
Pythonにおけるマルチスレッド、マルチプロセスとは
マルチスレッド、マルチプロセスは、複数のプログラムを同時に処理するための仕組みです。
詳しくはこちらの記事で説明していますが、ここでも軽く触れておきます。
マルチスレッド、マルチプロセスはWindowsやLinuxなどのOSが用意している仕組みであり、Pythonからはその仕組みを利用して、複数の処理を同時実行します
プロセスはEXCELやPowerPointの様な個々のアプリケーション、スレッドはアプリケーションの中に含まれるキー入力、計算、印刷などの各種処理のことです。
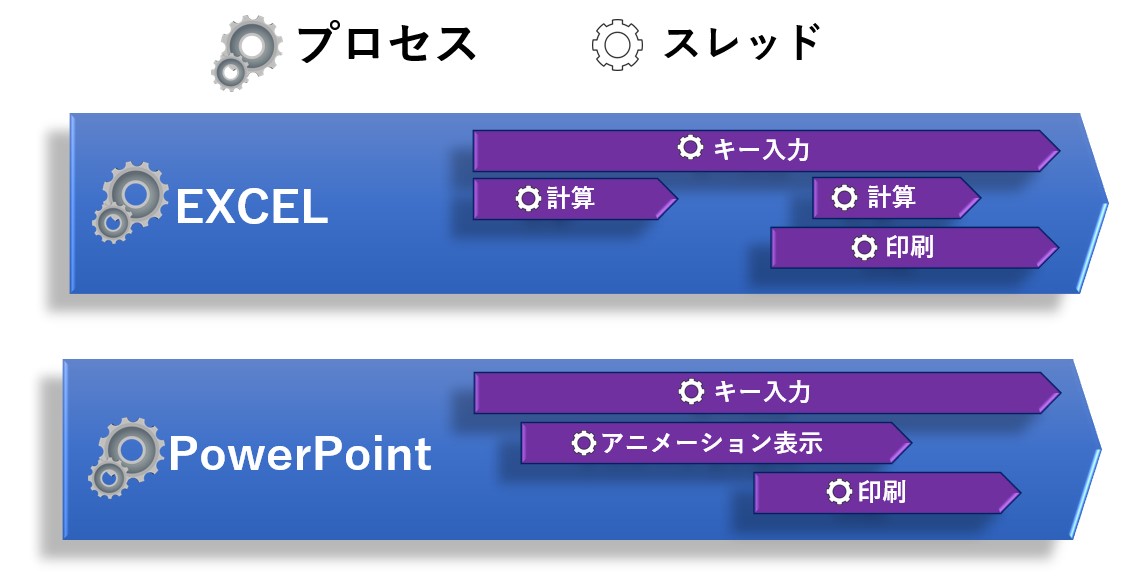
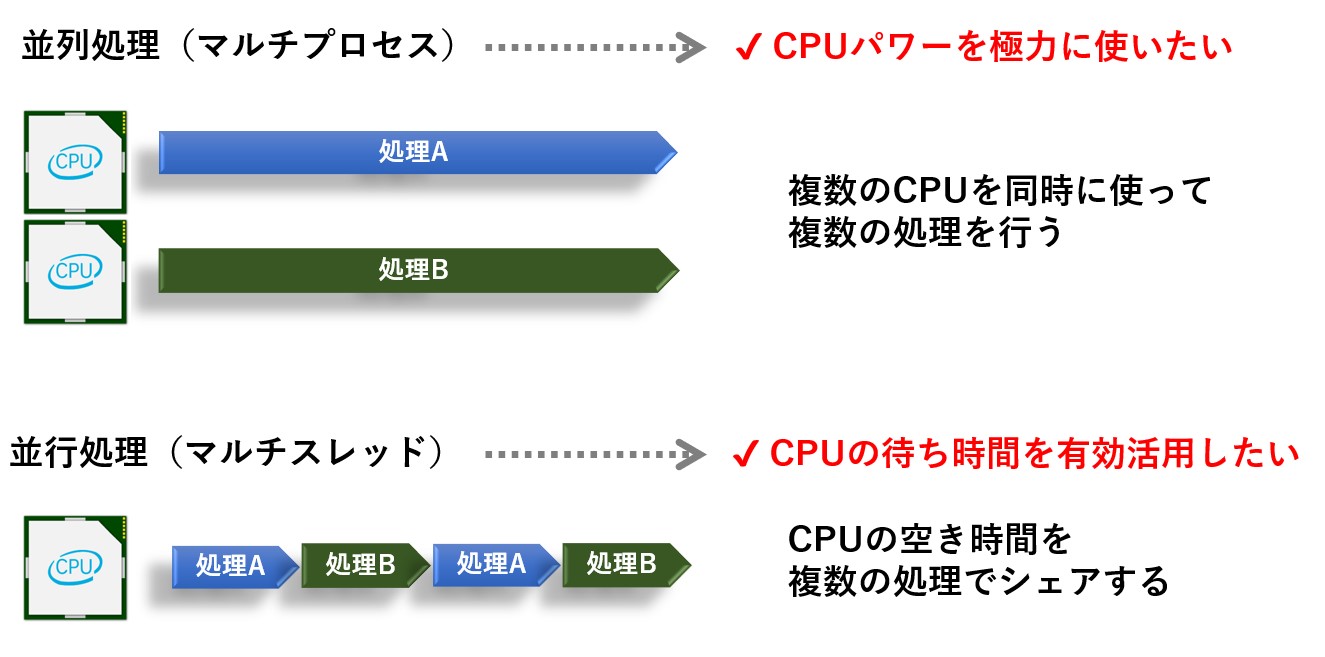
マルチプロセス、マルチスレッドという表現以外に、並列処理と並行処理という表現があります。
並列処理、並行処理は「複数処理を同時に行う方法」を意味しており、並列処理は2つの処理を並列に行うことに対し、並行処理は複数の処理を切り替えながら行う方法のことです。
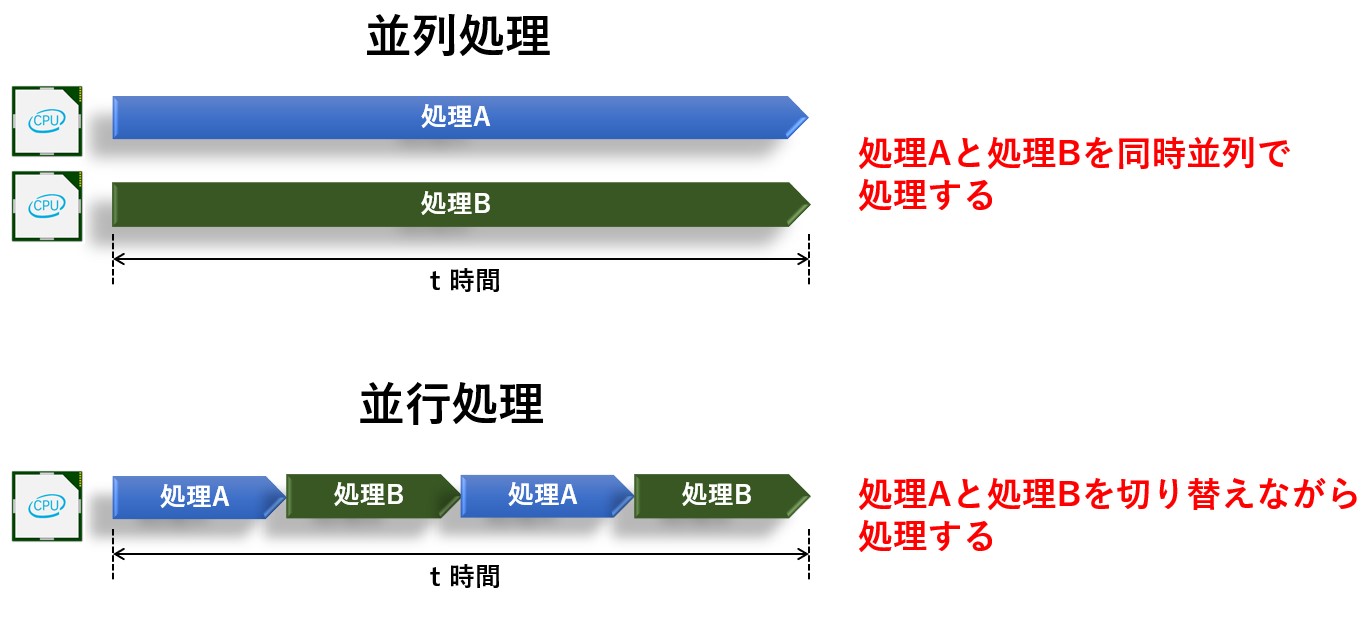
マルチプロセス、マルチスレッドが並列処理されるか並行処理されるかは言語やOSによって変わってくるのですが、Python の場合、マルチプロセスは並列処理、マルチスレッドは並行処理として動作します。
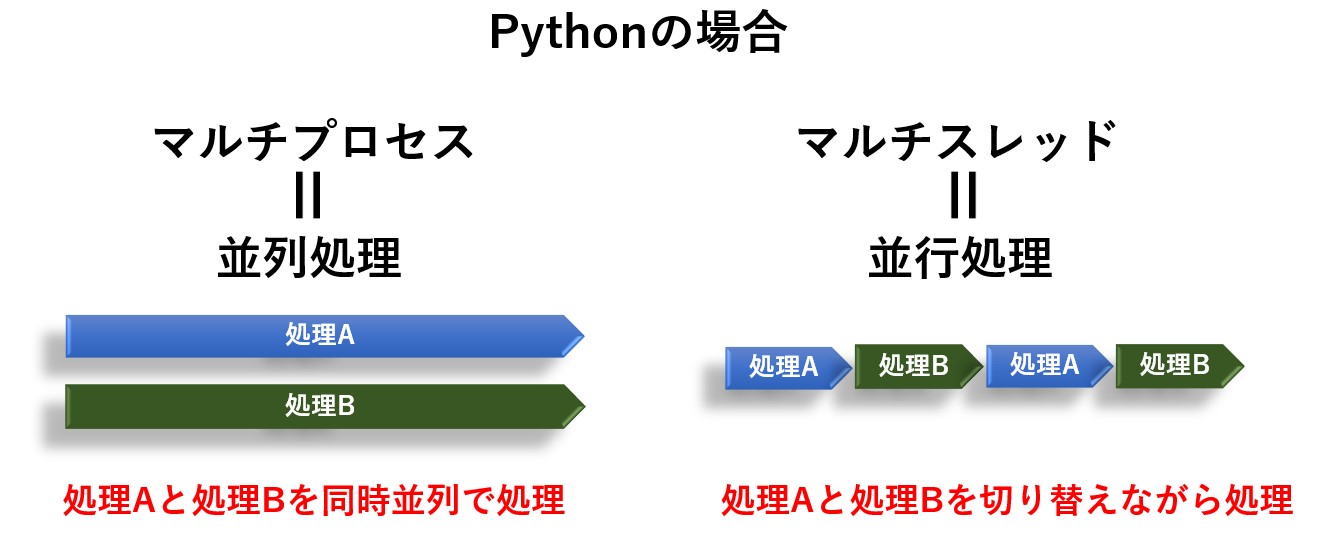
Python 3.2 より前のバージョンでは、マルチプロセスとマルチスレッドは別々のライブラリを使用していましたが、Python 3.2 以降は concurrent.futures というライブラリだけで両方を使うことが出来るようになりました。
この記事では、concurrent.futures を使ってそれぞれについて説明したいと思います。
マルチプロセスの実現方法
マルチプロセスを実現する場合、プログラムは次の様な構成になります。

まず、最初にライブラリをインポートしますので、次の1行を記述します。
from concurrent.futures import ProcessPoolExecutor
次に、並列で走らせたい処理をそれぞれ関数として記述します。
下記の例では、func_aとfunc_b という2つの関数を定義しています。
関数内で1秒のウェイトを入れているので、time をインポートしています。
import time
def func_a():
for i in range(5):
time.sleep(1)
print(f'func_a {i}')
def func_b():
for i in range(5):
time.sleep(1)
print(f'func_b {i}')
最後に、ProcessPoolExecutor と executor.submit を使って、func_a と func_b を別々のプロセスとして実行します。
尚、ProcessPoolExecutorの引数 max_workers は並列で走らせたい処理の上限です。
if __name__ == '__main__':
with ProcessPoolExecutor(max_workers=2) as executor:
executor.submit(func_a)
executor.submit(func_b)
max_workers に設定する値は、実際の数より大きくしても、逆に小さくしても良いのですが、大きくすると良くないという記事もあるため、実際の数と合わせる方が無難かもしれません。
それから注意点として、 if __name__ == ‘__main__’: という記述を省略すると下記の様なエラーが発生しますので、必ず記述して下さい。

マルチスレッドの実現方法
マルチスレッドの場合は、ProcessPoolExecutor を ThreadPoolExecutor に変更するだけです。

まず、次の1行でライブラリをインポートします。
from concurrent.futures import ThreadPoolExecutor
関数は共通で使うとして、ProcessPoolExecutor を ThreadPoolExecutor に変更すれば完了です。
if __name__ == '__main__':
with ThreadPoolExecutor(max_workers=2) as executor:
executor.submit(func_a)
executor.submit(func_b)
マルチプロセスとマルチスレッドの使い分けについて
では、マルチプロセスとマルチスレッドはどのように使い分ければよいのでしょう?
マルチプロセスは並列にすればするだけ処理時間が短くなりますが、スレッドは処理を切り替えて実行するだけなので、処理のトータル時間は同じです。
ただ、ファイル読み書きや通信などのI/Oが含まれている場合は、CPUの空き時間(待ち時間)が生じ、そこにスレッドが割り当てられるため処理時間は短くなります。
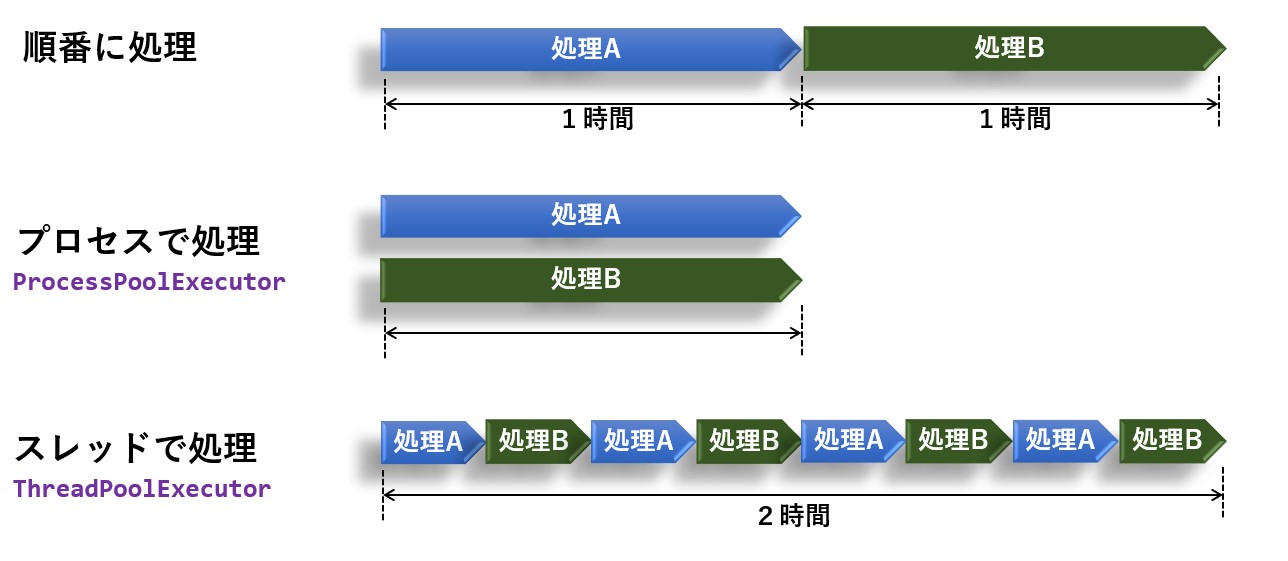
従って、重い処理に対して出来るだけCPUパワー(コア数)を使いたい場合はマルチプロセスが向いていて、ファイル読み書きや通信などのI/Oが多い処理を効率化したい場合はマルチスレッドが向いていると言えます。
マルチプロセスのオーバーヘッド
マルチプロセスの場合は処理時間が短く出来ると言いましたが、実はプロセスを起動するために若干の時間(オーバーヘッド)が生じます。
下記は Intel Core i5-9400 (2.90GHz) で計測した結果ですが、マルチスレッドに比べてマルチプロセスの方が287.5倍遅いという結果になりました。
| 2つの処理を100回実行した場合の時間 | 1回当たりの時間(オーバーヘッド) | 倍率 | |
|---|---|---|---|
| マルチプロセス | 9.21秒 | 0.046秒 | 287.5 |
| マルチスレッド | 0.032秒 | 0.00016秒 | 1 |
もっとも、マルチプロセスでも0.046秒なので通常の使い方だと無視できるオーバーヘッドですが、短時間の処理に対して何度もプロセスを実行すると、マルチスレッドより遅くなってしまうので注意が必要です。
from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import ProcessPoolExecutor
import time
def func_a():
pass
def func_b():
pass
if __name__ == '__main__':
t = time.time()
for i in range(100):
with ThreadPoolExecutor(max_workers=2) as executor:
executor.submit(func_a)
executor.submit(func_b)
print(f'Thread={time.time() - t}')
t = time.time()
for i in range(100):
with ProcessPoolExecutor(max_workers=2) as executor:
executor.submit(func_a)
executor.submit(func_b)
print(f'Process={time.time() - t}')
まとめ
今回はPythonのマルチプロセス、マルチスレッドについて、その方法について紹介しました。
マルチプロセス、マルチプロセスの実現方法は簡単だと思いますが、両者の違いについてはよく混同しがちなので、この記事でポイントを押さえていただければと思います。
マルチコアのCPUが当たり前の昨今ですが、意識してプログラミングしないとCPUパワーが生かしきれません。
今回の記事を参考に、CPUパワーを有効活用したプログラムを作っていただければと思います。
今回の記事が皆様のお役に立てれば幸いです。