
前回はワードクラウドについて紹介しましたが、今回は Python で TF-IDFによる文書の特徴抽出について紹介したいと思います。
今回もクラス化しているので、コピペですぐにお試しいただけます。
とりあえず使ってみたいという方は、是非この記事をご一読ください。
TF-IDFの概要
IF-IDFは、Term Frequency – Inverse Document Frequency の頭文字を取った名称です。
簡単にいうと、TFは「単語の登場頻度」、IDFは「文書間における単語のレア度」のことで、この2つを掛け合わせた値を意味します。
一般的に登場頻度が多い単語は重要であると考えられます。
しかし、複数の文書を比べてみた時、どの文章にもその単語が含まれていた場合、その単語の希少価値は少ないと考えます。
たとえば、A高校のサッカー部に所属するA君の日記と、B高校のバレー部に所属するBさんの日記を比べてみましょう。

A君、Bさん共に「授業」とか「先生」という単語が頻繁に登場することになるため、これらの単語は2つの日記の特徴を表していない為、価値が低いと考えられます。
一方、バレーに関する単語はAさんの日記にしかなく、サッカーに関する単語はBさんの日誌にしか登場しないので、これらは2つの日誌を比較した場合、レアな単語=日記を特徴付けている単語だと考えられます。
TF-IDFはこのような評価を数値で表すもので、文書の類似性を見たり、その文書の特徴を見出すときに使います。
インストール方法
Pythonで IF-TDF を行う場合、scikit-learn の他、形態素解析ライブラリ(MeCab、Janomeなど)が必要になります。
今回は、Janomeを使いますので、インストールは以下の様になります。
# python公式サイトからPythonをインストールした方 pip install scikit-learn pip install janome # anaconda で Pythonをインストールした方は # 既に scikit-learn がインストールされているので、 # janome のみインストールして下さい。 pip install janome # miniconda で Pythonをインストールした方 conda install scikit-learn pip install janome
IF-IDF の実行方法
以下の通り、必要なモジュールをimport します。
from sklearn.feature_extraction.text import TfidfVectorizer from janome.tokenizer import Tokenizer
TF-IDFを求める手順は次の様になります。
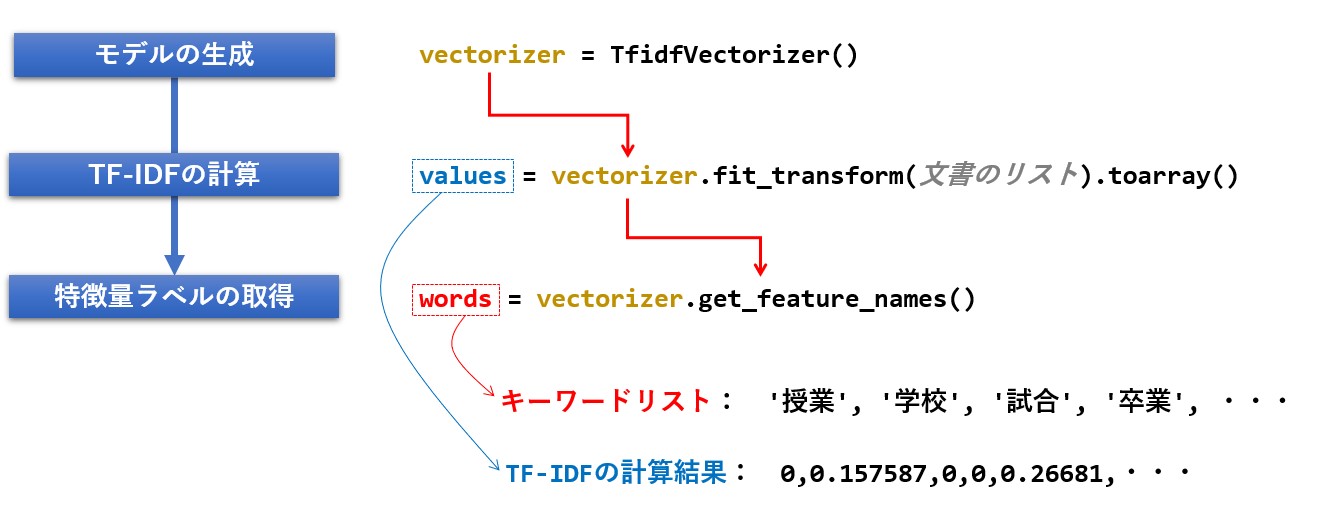
TF-IDFを計算するためのインプットは、形態素解析によって分かち書きされた文書になります。
リスト形式で複数の文書をfit_transform() メソッドに渡すことで、TF-IDF値が計算されます。
以下はそのサンプルプログラムです。
#TF-IDFを求めたい文書のリスト(実際には分かち書き文書又は単語の羅列)
docs = [
'今日 学校 体育 授業 バレー トス レシーブ 授業 先生 クラブ バレー 放課後',
'今日 放課後 クラブ 活動 サッカー 試合 サッカー 合宿 ゴール キーパー'
]
# モデルの生成
vectorizer = TfidfVectorizer(smooth_idf = False)
# TF-IDFの計算
values = vectorizer.fit_transform(docs).toarray()
# 特徴量ラベルの取得
words = vectorizer.get_feature_names()
#結果のプリント
print(values)
print(words)
結果は次の様になります。

words には、指定された全ての文書から抽出された単語が、重複無しで格納されています。
そして、values には、文書毎の単語に対するTF-IDF値が格納されています。
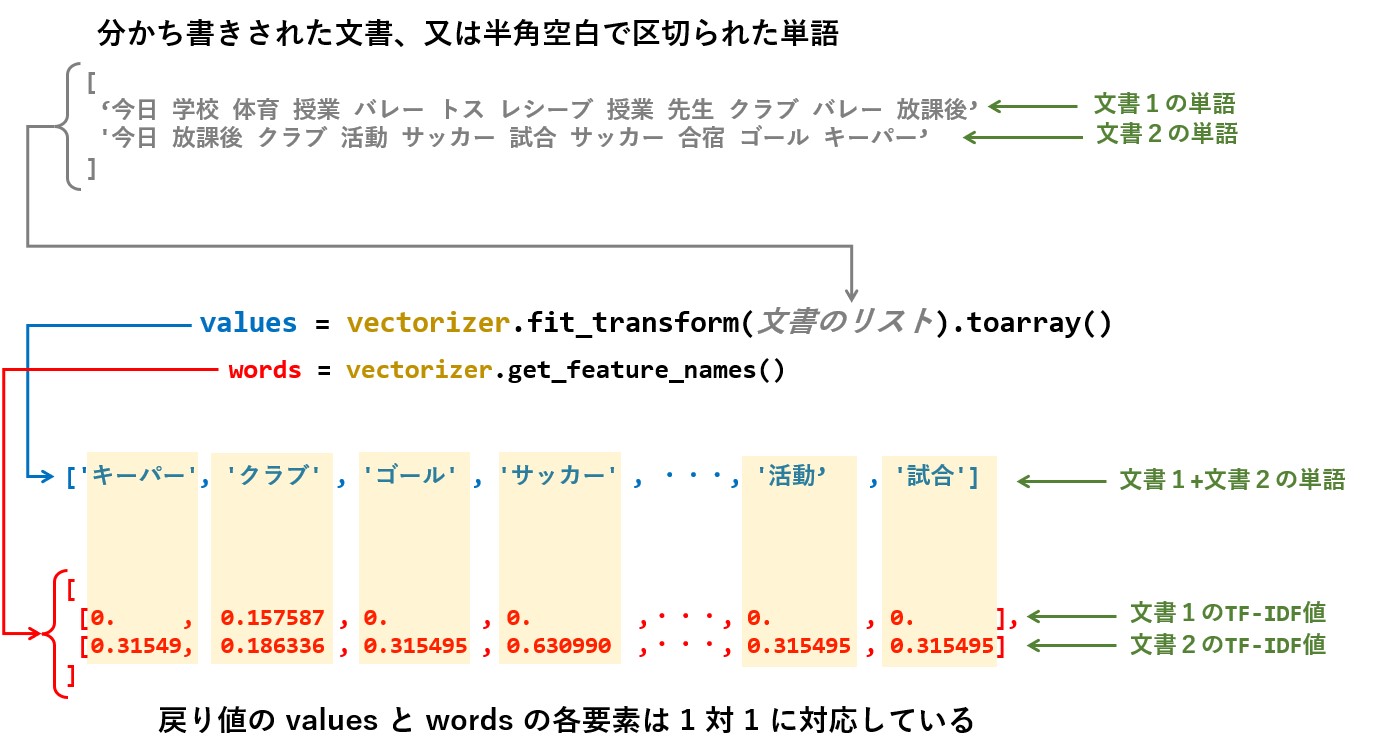
words と values の要素は1対1で対応しているため、文書ごとに対で取り出してTF-IDF値の大きい順に並べ替えれば、各文書ごとの特徴が理解し易くなります。
下記はそのサンプルです。
一旦 DataFrame に入れて縦横変換を行ってから並べ替えを行っています。
df = pd.DataFrame(values, columns = words)
print(df.T.sort_values(by=0,ascending=False)[0])
print('---------------')
print(df.T.sort_values(by=1,ascending=False)[1])

TF-IDF クラスについて
では、さっそく自作したTF-IDFクラスの概要、リファレンス、ソースコードの順に紹介していきたいと思います。
クラスの概要
TF-IDFは複数の文書を使った分析になるので、add_file 又は add_text メソッドで文書を追加していきます。
追加し終えたら、create メソッドでTF-IDFを計算します。
このクラスは計算結果を取得するためのメソッドが2つあり、1つは 文書毎のTF-IDFの値を取得する top_words、もう1つは文書毎の単語の出現頻度を取得する word_count です。
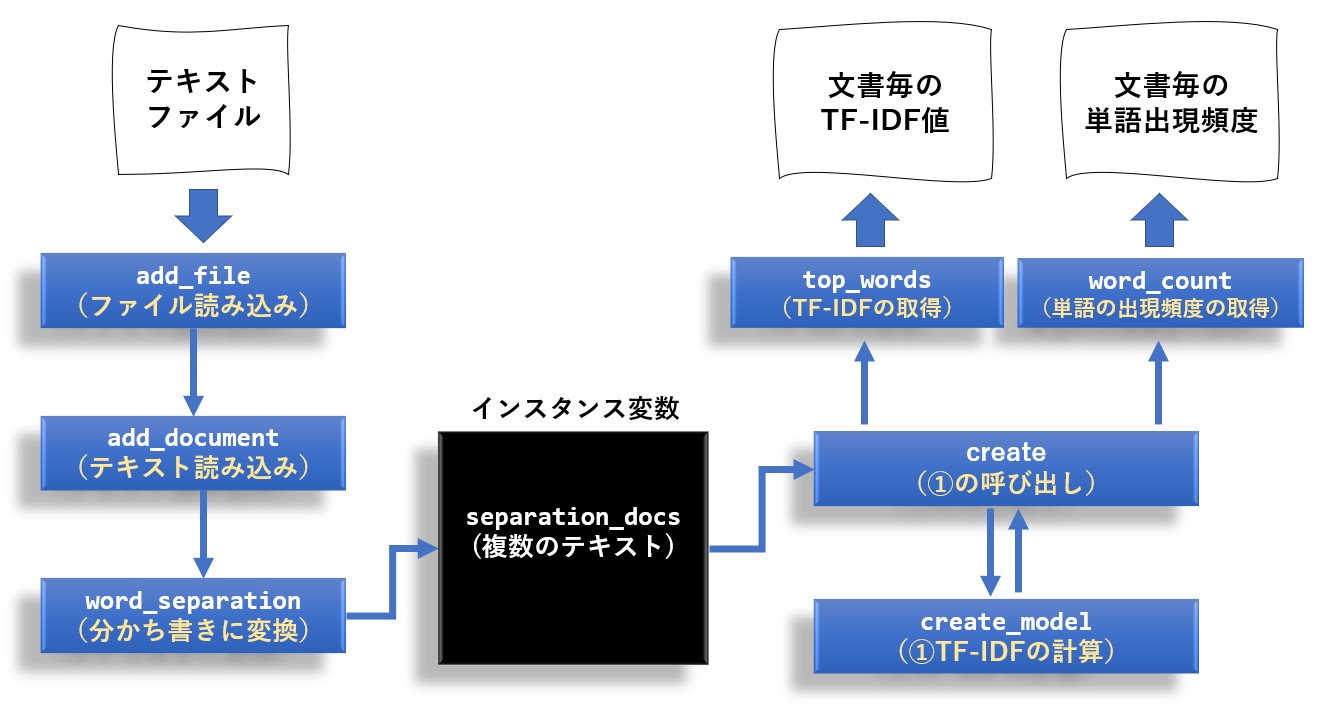
リファレンス
クラス名は TfIdf で、メソッドは次の8つがあります。
| 機能 | メソッド仕様 | 戻り値 |
|---|---|---|
| コンストラクタ | __init__() | なし |
| ファイルの追加 | add_file( title, #タイトル filename, #入力ファイル名 encoding=’utf-8′ #エンコード名 ) |
なし |
| テキストの追加 | add_text( title, #タイトル document #入力文書 ) |
なし |
| TF-IDFの計算結果を DataFrameに格納 |
create() | DataFrame |
| 分かち書きへの変換 (形態素解析) |
word_separation( text #文書 ) |
‘aaa bbb ccc ・・・’ |
| TF-IDFのモデル作成 | create_model( separating_docs #複数の文書 ) |
[aaa,bbb,ccc,・・・], [ [0.272,0,632,・・・], [3.2533,0,235,・・・] ] |
| 文書毎のTF-IDF値の取得 | top_words( cnt = 10 #上位n個の指定 ) |
{ ‘aaa’ : dataframe ,’bbb’ : dataframe } |
| 文書毎の単語登場頻度の取得 | word_count( cnt = 10 #上位n個の指定 ) |
{ ‘aaa’ : dataframe ,’bbb’ : dataframe } |
createメソッドの戻り値
create メソッドの戻り値 は以下の通りで、column に抽出された単語がセットされ、1行1文書として、文書ごとの単語のTF-IDF値を格納したDataFrameを返します。

top_words の戻り値
top_words メソッドの戻り値は以下の通りで、上記のDataFrameから1行づつ取り出し、TF-IDFの値で並べ替えた結果を辞書に格納して返します。

word_count の戻り値
word_count メソッドの戻り値は top_words と同じで、TF-IDF値の代わりに出現頻度が格納されています。
使い方
使い方は非常に簡単で、次の順番にメソッドを呼ぶだけです。
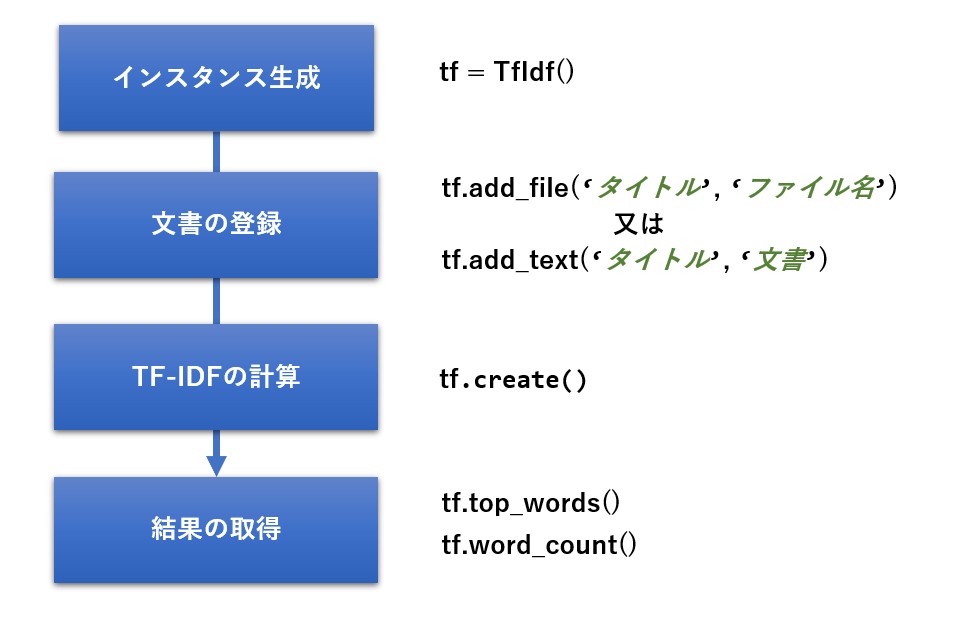
tf = TfIdf()
tf.add_file('スタートレック','p:/target1.txt')
tf.add_file('ギャラクティカ','p:/target2.txt')
tf.add_file('スターゲート・アトランティス','p:/target3.txt')
tf.create()
print(tf.top_words())
print(tf.word_count())
検証で使ったPCはWindows10マシンなので、サンプルソースはPドライブ直下に保存した startreck.txt というファイルを読み込むようになっています。
また、ファイルの中身は以下の通りです。
target1.txt
スタートレックは、22世紀から24世紀の話である。
設定では、2026年から2053年にかけて発生した第三次世界大戦により、6億人の犠牲者と文明の崩壊が起きている。
2063年にゼフラム・コクレーンがワープエンジンを開発、試験飛行中にバルカン時に発見され、ファーストコンタクトを果たした。
2151年には初代エンタープライズ号「NX-01」が竣工し、クリンゴンとのファーストコンタクトを果たしている。
2153年にロミュラン人との戦争が勃発、2161年に地球連合、バルカン、アンドリアが中心になり惑星連邦が設立された。
地球人は銀河系内の約4分の1の領域に進出し、様々な異星人との交流を行っている。
既に貧困や戦争などは根絶されており、見た目や無知から来る偏見、差別も存在しない、理想的な世界となっている。
レプリケーターの登場により貨幣経済は無くなり、人間は富や欲望ではなく人間性の向上を目指して働いている。
しかし、個人財産は存在しており、ワイナリーや宇宙船を所有する一部の恵まれた人々が存在する。
target2.txt
GALACTICAは2005年1月から2009年3月にかけてアメリカのSF専門チャンネル「Sci-Fi」で放送されたSFテレビドラマである。
2003年12月に2話(計4時間)のパイロット版が放映され、高評価を受けたことでTVシリーズが制作された。
12の惑星に植民地を持つ人類(地球人ではない)と機械生命体であるサイロンとの戦争が勃発。
奇跡的に生き残った人類は宇宙空母GALACTICAと民間宇宙船と共に220隻の艦隊を組み、敵の追撃を交わしながら伝説の惑星「地球」を目指すというストーリである。
1978年にTVで放送された「宇宙空母ギャラクティカ」のリメイク版であるため、基本的な設定は踏襲されているものの、人間と見分けが付かない人型サイロンの登場や、サイロンの内部分裂、人類に味方するサイロンとの協力など、より深い内容に仕上がっている。
このほか、スピンオフ作品として、「The Plan/神の誤算」、「RAZOR/ペガサスの黙示録」、「BLOOD&CHROME/最高機密指令」が制作された。
target3.txt
スターゲイト・アトランティスは、1994年のSF映画「スターゲイト」を受けてTVドラマ化された「スターゲイト SG-1」のスピンオフ作品である。
2004年から2008年にかけて5シーズン100話が制作された。
スターゲイトは、宇宙四大種族の中の一種族であるエンシェントが作り出した星間移動装置(通称スターゲイト)がエジプトで発見されたことをきっかけに、別の惑星に連れ去られた古代地球人の末裔の存在を知り、支配者であるラーからの解放を勝ち取るというストーリであった。
スターゲイト SG-1は、スターゲイトの1年後が舞台となっており、スターゲイトを使った惑星間移動を通して、侵略者との戦い、惑星探査、異種族との交流を繰り広げるといったストーリーとなっている。
そして、スターゲイト・アトランティスは、太古に海中に水没したとされるアトランティス大陸が、実は別銀河にある都市型の宇宙船だったという設定をベースに、そこに送り込まれた隊員たちの活躍が描かれた作品である。
このクラスを使った実行結果は以下の様になりました。
まずはTF-IDF の結果(ベスト10)です。
ギャラクティカの結果を見ると「サイロン」というキーワードを「サイロ」としても解釈しているようで、形態素解析にユーザー辞書を使うなどの改善が必要ですね。
| スタートレック | ギャラクティカ | スターゲート・アトランティス |
| バルカン 0.272358 世紀 0.272358 世界 0.272358 ファースト 0.272358 コンタクト 0.272358 人間 0.182401 文明 0.136179 犠牲 0.136179 無知 0.136179 大戦 0.136179 |
人類 0.376665 galactica 0.251110 サイロン 0.251110 空母 0.251110 サイロ 0.251110 宇宙 0.168171 sf 0.168171 tv 0.168171 基本 0.125555 パイロット 0.125555 |
スターゲイト 0.808280 アトランティス 0.269427 種族 0.179618 sg 0.179618 惑星 0.128383 作品 0.120292 ストーリー 0.089809 エジプト 0.089809 シーズン 0.089809 異種 0.089809 |
次に、単語出現頻度(ベスト10)の結果です。
| スタートレック | ギャラクティカ | スターゲート・アトランティス |
| 世紀 2 世界 2 バルカン 2 ファースト 2 コンタクト 2 人間 2 レック 1 大戦 1 犠牲 1 文明 1 |
人類 3 GALACTICA 2 月 2 SF 2 TV 2 惑星 2 サイロ 2 宇宙 2 空母 2 サイロン 2 |
スターゲイト 7 惑星 3 スターゲイト・アトランティス 2 SG 2 作品 2 種族 2 SF 1 映画 1 TV 1 ドラマ 1 |
ソースコード
最後に、クラスの全ソースコードを紹介しておきます。
from sklearn.feature_extraction.text import TfidfVectorizer
from janome.tokenizer import Tokenizer
import re
import pandas as pd
import codecs
from collections import Counter
class TfIdf:
def __init__(self):
"""
コンストラクタ
"""
# 分かち書きの文書を保持する変数
self.separation_docs = {}
self.df = None
def create(self):
"""
TF-IDFの実行
"""
#TF-IDFの実行
names,values = self.create_model(self.separation_docs.values())
#結果をDataFrameに格納
self.df = pd.DataFrame(values, columns = names,index = self.separation_docs.keys())
return self.df
def word_separation(self,text):
"""
形態素解析により一般名詞と固有名詞のリストを作成
---------------
Parameters:
text : str テキスト
"""
token = Tokenizer().tokenize(text)
words = []
for line in token:
tkn = re.split('\t|,', str(line))
# 名詞のみ対象
if tkn[1] in ['名詞'] and tkn[2] in ['一般', '固有名詞']:
words.append(tkn[0])
return ' ' . join(words)
def create_model(self,separating_docs):
"""
TF-IDFの計算を行う
---------------
Parameters:
documents : [str] 分かち書きされた文書のリスト
"""
# モデルの生成
vectorizer = TfidfVectorizer(smooth_idf = False)
# TF-IDF行列の計算
values = vectorizer.fit_transform(separating_docs).toarray()
# 特徴量ラベルの取得
feature_names = vectorizer.get_feature_names()
return feature_names,values
def add_file(self,title,filename,encoding='utf-8'):
'''
ファイルの読み込み
Parameters:
--------
filename : str TF-IDFしたい文書が書かれたファイル名
'''
with codecs.open(filename,'r',encoding,'ignore') as f:
self.add_document(title,f.read())
def add_document(self,title,document):
'''
テキストの読み込み
Parameters:
--------
document : str TF-IDFしたい文書
'''
# 形態素解析で分かち書きした文書をインスタンス変数に格納
self.separation_docs[title] = self.word_separation(document)
def top_words(self,cnt = 10):
'''
TF-IDF 上位nの取得
Parameters:
--------
cnt : int 上位からの取得件数
'''
res = {}
for n,title in enumerate(self.separation_docs):
res[title] = (self.df[n:n+1].T.sort_values(by=title, ascending=False).head(cnt)).rename(columns={title:'TFIDF'})
return res
def word_count(self,cnt = 10):
'''
出現回数上位nの取得
Parameters:
--------
cnt : int 上位からの取得件数
'''
res = {}
for key,value in self.separation_docs.items():
data = Counter(value.split(' ')).most_common(cnt)
res[key] = pd.DataFrame([v for k,v in data],columns=['Count'],index=[k for k,v in data])
return res
まとめ
今回は機械学習ライブラリ sklearn に含まれている TF-IDFの関数 TfidfVectorizer と、形態素解析器に janome を組み合わせて、複数文書のTF-IDF、並びに単語の出現頻度を計算する方法を紹介しました。
今回は単純に文書から名詞だけを抜き出し、辞書も標準のものを使いましたが、辞書に neologd を使ったり、一部動詞を含めたりすると、また違った結果が得られると思います。
とりあえずTF-IDFを手軽に試してみたい方は、ソースコードをコピペしてお試しください。
この記事が皆様のお役に立てば幸いです。