
この記事は、最新の記事の一部です。 AI研究。
人間にとって、変形可能なオブジェクトの操作は、硬いオブジェクトの処理よりもそれほど難しくありません。 私たちは自然にそれらを形作り、折り畳み、さまざまな方法で操作し、それでもそれらを認識することを学びます。
しかし、ロボットや人工知能システムの場合、変形可能なオブジェクトを操作することは大きな課題です。 生地のボールをピザの皮に形作るためにロボットが取らなければならない一連のステップを考えてみてください。 生地の形が変化するのを追跡すると同時に、作業の各ステップに適したツールを選択する必要があります。 これらは、より予測可能な状態を持つ剛体オブジェクトの処理においてより安定している現在のAIシステムにとって困難なタスクです。

ヒューマノイドのご挨拶
今すぐ購読して、お気に入りのAIストーリーの毎週の要約をご覧ください
現在、MIT、カーネギーメロン大学、カリフォルニア大学サンディエゴ校の研究者によって開発された新しい深層学習技術は、変形可能なオブジェクトの処理においてロボットシステムをより安定させる可能性を示しています。 と呼ばれる DiffSkill、この手法では、深いニューラルネットワークを使用して単純なスキルを学習し、スキルを組み合わせて複数のステップとツールを必要とするタスクを解決するための計画モジュールを使用します。
強化学習と深層学習による変形可能なオブジェクトの処理
AIシステムがオブジェクトを処理する場合は、その状態を検出して定義し、将来どのように見えるかを予測できる必要があります。 これは、リジッドオブジェクトで大部分が解決された問題です。 トレーニング例の良いセットで、 ディープニューラルネットワーク さまざまな角度から剛体を検出できるようになります。 ただし、変形可能なオブジェクトに関しては、可能な状態の空間ははるかに複雑になります。
「剛体の場合、その状態を6つの数字で表すことができます。XYZ座標を表す3つの数字と、方向を表す3つの数字です」Xingyu Lin、Ph.D. CMUの学生であり、DiffSkill論文の筆頭著者であると、TechTalksに語った。
「しかし、生地や布などの変形可能なボディには無限の自由度があるため、それらの状態を正確に記述することははるかに困難です。 さらに、それらが変形する方法も、剛体と比較して数学的な方法でモデル化するのが困難です。」
微分可能な物理シミュレータの開発により、変形可能なオブジェクト操作タスクを解決するための勾配ベースの方法の適用が可能になりました。 これは、従来の方法とは対照的です 強化学習 純粋な試行錯誤の相互作用を通じて環境とオブジェクトのダイナミクスを学習しようとするアプローチ。
DiffSkillはに触発されました PlasticineLab、2021年のICLR会議で発表された微分可能な物理シミュレータ。PlasticineLabは、微分可能なシミュレータが短期間のタスクに役立つことを示しました。

しかし、微分可能なシミュレーターは、複数のステップとさまざまなツールの使用を必要とする長期的な問題に依然として苦労しています。 微分可能なシミュレータに基づくAIシステムでは、エージェントが完全なシミュレーション状態と環境の関連する物理パラメータを知っている必要もあります。 これは、エージェントが通常、視覚および深度感覚データ(RGB-D)を通じて世界を知覚する、実際のアプリケーションでは特に制限されます。
「私たちは抽出できるかどうか尋ね始めました [the steps required to accomplish a task] スキルとして、またスキルに関する抽象的な概念を学び、スキルを連鎖させてより複雑なタスクを解決できるようにします」とLin氏は述べています。
DiffSkillは、AIエージェントが微分可能な物理モデルを使用してスキルの抽象化を学習し、それらを構成して複雑な操作タスクを実行するフレームワークです。
リンの過去の仕事は、布、ロープ、液体などの変形可能なオブジェクトの操作に強化学習を使用することに焦点を当てていました。 DiffSkillの場合、彼は生地の操作がもたらす課題のために生地の操作を選択しました。
「生地の操作は、ロボットグリッパーでは簡単に実行できないため、特に興味深いものですが、さまざまなツールを順番に使用する必要があります。人間は得意ですが、ロボットが行うことはあまり一般的ではありません」とLin氏は述べています。
トレーニングが完了すると、DiffSkillはRGB-D入力のみを使用して一連の生地操作タスクを正常に実行できます。
ニューラルネットワークで抽象的なスキルを学ぶ
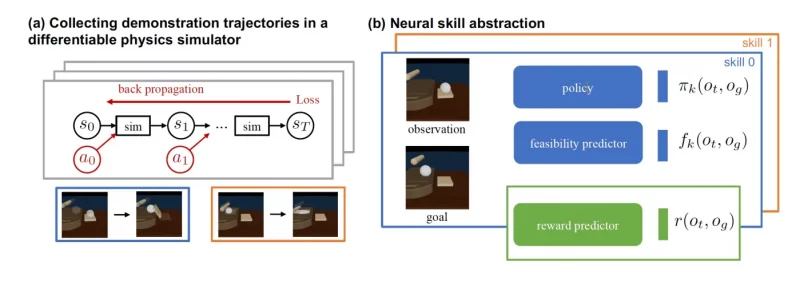
DiffSkillは、2つの主要なコンポーネントで構成されています。 ニューラルネットワーク 個々のスキルと、長期的な課題を解決するためのスキルを構成する「プランナー」を学びます。
DiffSkillは、微分可能な物理シミュレータを使用して、スキルアブストラクタのトレーニング例を生成します。 これらのサンプルは、ローラーを使用して生地を広げたり、へらを使用して生地を移動したりするなど、単一のツールで短期間の目標を達成する方法を示しています。
これらの例は、RGB-Dビデオとしてスキルアブストラクタに提示されます。 画像の観察を前提として、スキルアブストラクタは、目的の目標が実現可能かどうかを予測する必要があります。 モデルは、その予測を物理シミュレーターの実際の結果と比較することにより、パラメーターを学習して調整します。
生地のような変形可能なオブジェクトのロボット操作には、さまざまなツールの使用についての長期的な推論が必要です。 私たちのメソッドDiffSkillは、微分可能なシミュレーターを利用して、これらの困難なタスクのスキルを学習および構成します。 #ICLR2022
Webサイト: https://t.co/1JFDUxfIyC pic.twitter.com/rNRJ1XskGB— Xingyu Lin(@ Xingyu2017) 2022年4月27日
同時に、DiffSkillは変分オートエンコーダー(VAE)をトレーニングして、物理シミュレーターによって生成された例の潜在空間表現を学習します。 VAEは、重要な機能を保持し、タスクに関係のない情報を破棄する低次元の空間で画像をエンコードします。 VAEは、高次元の画像空間を潜在空間に転送することにより、DiffSkillが長い視野を計画し、感覚データを観察して結果を予測できるようにする上で重要な役割を果たします。
VAEをトレーニングする際の重要な課題の1つは、適切な機能を学習し、物理シミュレーターによって生成されたものとは視覚データの構成が異なる現実世界に一般化することを確認することです。 たとえば、ローラーピンやテーブルの色はタスクに関係ありませんが、ローラーの位置と角度、および生地の位置は関係があります。
現在、研究者は「ドメインランダム化」と呼ばれる手法を使用しています。これは、背景や照明などのトレーニング環境の無関係なプロパティをランダム化し、ツールの位置や向きなどの重要な機能を保持します。 これにより、VAEを実世界に適用した場合の安定性が高まります。
「シミュレーションと現実の世界で異なる可能性のあるすべてのバリエーションをカバーする必要があるため、これを行うのは簡単ではありません。 [known as the sim2real gap]」とリンは言った。 「より良い方法は、シーンの表現として3Dポイントクラウドを使用することです。これは、シミュレーションから実世界への転送がはるかに簡単です。 実際、私たちは点群を入力として使用するフォローアッププロジェクトに取り組んでいます。」
長期的な変形可能オブジェクトタスクの計画
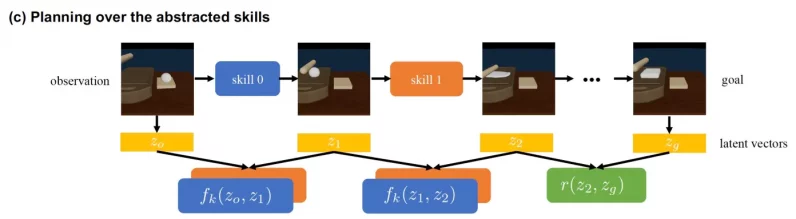
スキルアブストラクタがトレーニングされると、DiffSkillはプランナーモジュールを使用して長期的なタスクを解決します。 計画担当者は、初期状態から目的地に到達するために必要なスキルの数と順序を決定する必要があります。
このプランナーは、スキルの可能な組み合わせとそれらがもたらす中間的な結果を繰り返します。 ここでは、変分オートエンコーダーが便利です。 DiffSkillは、完全な画像の結果を予測する代わりに、VAEを使用して、最終目標に向けた中間ステップの潜在空間の結果を予測します。
抽象スキルと潜在空間表現の組み合わせにより、初期状態から目標までの軌道を描くことがはるかに計算効率が高くなります。 実際、研究者は検索機能を最適化する必要はなく、すべての組み合わせの徹底的な検索を使用しました。
「私たちはスキルを計画しており、期間はそれほど長くないので、計算はそれほど多くありません」とリンは言いました。 「この徹底的な検索により、プランナーのスケッチを設計する必要がなくなり、私たちが試した限られたタスクではこれを観察しませんでしたが、より一般的な方法で設計者が考慮しない新しいソリューションにつながる可能性があります。 さらに、より高度な検索手法も適用できます。」
DiffSkillの論文によると、「最適化は、単一のNVIDIA2080TiGPUでスキルの組み合わせごとに約10秒で効率的に実行できます。」
DiffSkillでピザ生地を準備する
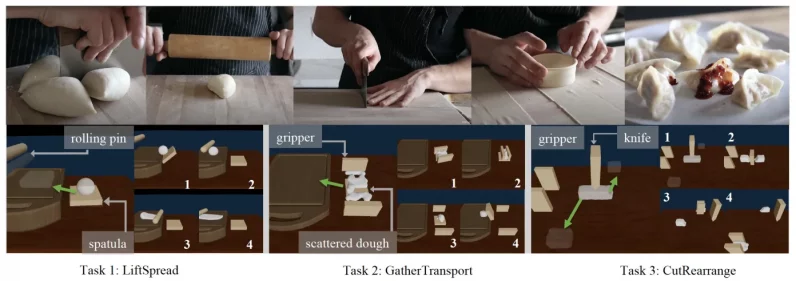
研究者は、2つのモデルフリー強化学習アルゴリズムと物理シミュレーターのみを使用する軌道オプティマイザーを含む、変形可能なオブジェクトに適用されたいくつかのベースラインメソッドに対してDiffSkillのパフォーマンスをテストしました。
モデルは、複数のステップとツールを必要とするいくつかのタスクでテストされました。 たとえば、タスクの1つでは、AIエージェントはヘラで生地を持ち上げ、まな板の上に置き、ローラーで広げる必要があります。
結果は、DiffSkillが、感覚情報のみを使用して長期にわたる複数のツールのタスクを解決する上で、他の手法よりも大幅に優れていることを示しています。 実験は、十分に訓練された場合、DiffSkillのプランナーは、初期状態と目標状態の間の適切な中間状態を見つけ、タスクを解決するための適切なスキルのシーケンスを見つけることができることを示しています。
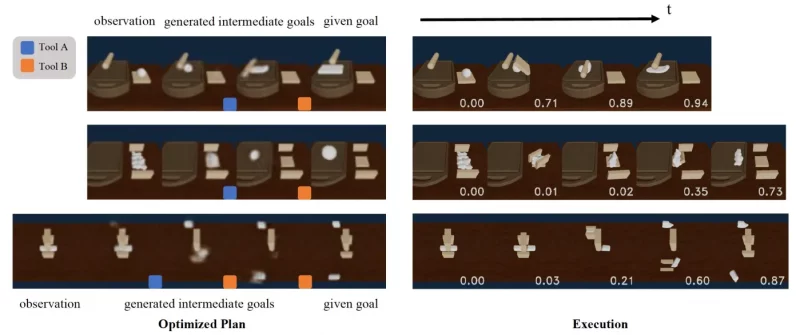
「1つのポイントは、一連のスキルが非常に重要な時間的抽象化を提供し、長期的な視野で推論できることです」とLin氏は述べています。 「これは、人間がさまざまなタスクに取り組む方法にも似ています。次の1秒ごとに何をすべきかを考えるのではなく、さまざまな時間的抽象化で考えるのです。」
ただし、DiffSkillの容量にも制限があります。 たとえば、3段階の計画が必要なタスクの1つを実行すると、DiffSkillのパフォーマンスが大幅に低下します(ただし、他の手法よりも優れています)。 Linはまた、場合によっては、実現可能性予測子が誤検知を生成すると述べました。 研究者たちは、より良い潜在空間を学ぶことがこの問題の解決に役立つと信じています。
研究者はまた、より長い期間のタスクに使用できるより効率的なプランナーアルゴリズムを含む、DiffSkillを改善するための他の方向性を模索しています。
リンは、いつの日か、実際のピザ製造ロボットでDiffSkillを使用できるようになることを望んでいます。 「私たちはまだこれから遠く離れています。 制御、sim2real転送、および安全性からさまざまな課題が発生します。 しかし、私たちは今、いくつかの長期的なタスクを試すことに自信を持っています」と彼は言いました。
この記事はもともとベンディクソンによって公開されました TechTalks、テクノロジーのトレンド、それが私たちの生活やビジネスのやり方にどのように影響するか、そしてそれらが解決する問題を調査する出版物。 しかし、テクノロジーの邪悪な側面、新しいテクノロジーのより暗い意味、そして私たちが注意する必要があることについても説明します。 元の記事を読むことができます ここ。
The post 新しい深層学習技術がピザ製造ロボットへの道を開く appeared first on Gamingsym Japan.