
使用している場合 Solr しばらくの間、Solrコンテナーをオーケストレーションする方法を学びたい場合は、適切な場所に来ました。 通常のApacheSolrチュートリアルとは異なり、このチュートリアルに没頭して、KubernetesApacheSolrクラスターを活用します。
このチュートリアルでは、サーブレットコンテナ内で全文検索サーバーを実行し、ApacheSolrでKubernetesを使用してコンテナを管理する方法を学習します。
読んで、オーケストレーションを開始してください!
前提条件
このチュートリアルは、実践的なデモンストレーションで構成されています。 フォローしたい場合は、次のものが揃っていることを確認してください。
- ミニクベ 作成され、実行されているノード VirtualBox –このチュートリアルでは、Minikubev1.25.2とVirtualBox6.1を使用します。
- Linuxマシン–このチュートリアルではUbuntu20.04.3LTSを使用します。
ApacheSolrコンテナーのポッドの作成
クラスターで作業する前に、Solrコンテナーが存在して管理されるポッドが必要です。 YAMLファイルを作成します kind に設定 Deployment、コンテナを構築するイメージを指定してから、ポートを初期化します。
ターミナルで直接コマンドを実行する代わりに、ファイルに命令を書き込む宣言型アプローチのみを使用します。
Apache Solrコンテナーのポッドを作成するには:
1.プロジェクトのすべてのファイルを保存するために、希望する名前でプロジェクトディレクトリを作成します。 このチュートリアルでは、次のプロジェクトディレクトリを使用します kube_solr。
2.次に、プロジェクトディレクトリに新しいYAMLファイルを作成します(kube_solr)お好みのテキストエディタを使用して、以下のYAMLコードをYAMLファイルに貼り付けます。 YAMLファイルに好きな名前を付けますが、YAMLファイルには名前が付けられます deploy.yaml このチュートリアルでは。
以下のコードは、それぞれがSolrコンテナーを含む3つのポッドを作成します。
apiVersion: apps/v1
kind: Deployment
metadata:
name: solr-deployment # Names your deployment.
labels: # Used to organize and select subsets of Kubernetes objects.
app: solrApp
spec:
# State the number of replicas of the application you need.
replicas: 3
# Defines how the Deployment finds which Pods to manage.
selector:
matchLabels:
app: solrApp
template:
metadata:
labels:
app: solrApp
spec:
containers:
# State the image's name on Docker Hub to build the container from.
- name: solr
image: solr
# State container port for Solr server (8983).
ports:
- containerPort: 8983
name: solrapp3.次に、 kubectly apply 以下のコマンドを使用して、で設定した構成を適用します。 deploy.yaml ファイル。
kubectl apply -f deployment.yaml4.最後に、以下を実行します kubectl get 使用可能なすべてのポッドを返すコマンド。
以下に、Solrコンテナーの3つのレプリカのポッドが作成され、正常に実行されていることを示します。
インターネットとローカルマシンの速度によっては、ポッドでのコンテナのアクティブ化が完了するまでに20〜30分かかる場合があります。

Solrサービスの作成
これでポッドの準備が整いましたが、サービスを作成してポッドに永続的なIPアドレスを設定する必要があります。 ポッドの再起動時に同じIPアドレスを維持するには、永続的なIPアドレスを設定する必要があります。
1.新しいYAMLファイルを作成し、以下のコードをYAMLファイルに入力します。 YAMLに好きな名前を付けますが、ファイルの名前は solr-service.yaml このチュートリアルでは。
以下のコードには、新しいコードを作成するための手順が含まれています Service 名前の付いたオブジェクト solr-service、ポートをターゲットにします 8983 ポッドの app=solrApp ラベル。
apiVersion: v1
kind: Service
metadata:
labels:
app: solrApp
name: solr-service
spec:
selector:
# Set of Pods targeted by a Service. Matches pods with the label solrApp.
app: solrApp
ports:
- port: 8983 # Port exposed by the service.
targetPort: 8983 # Target port 8983 on any pod.2.次に、以下のコマンドを実行して、次のようにKubernetesリソースを作成します。 solr-service.yaml。
kubectl apply -f solr-service.yaml
最後に、以下を実行します kubectl describe に関する詳細を表示するコマンド solr-service service あなたが作成しました。
kubectl describe service solr-service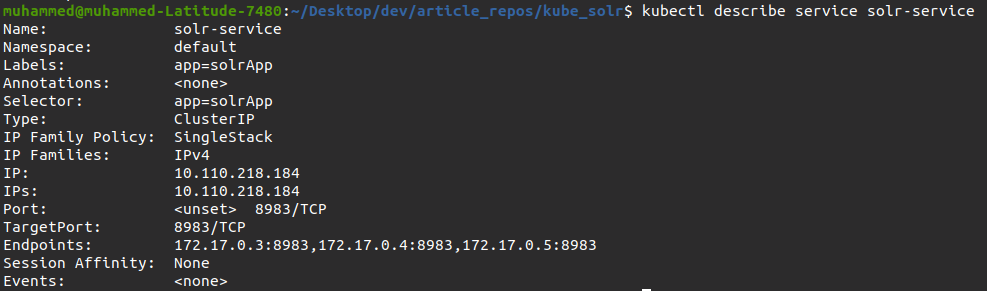
SSH経由でMinikubeサーバーに接続する
Kubernetesリソースはすべてセットアップされていますが、Solrコンテナーをどのように管理しますか? まず、SSH経由でMinikubeサーバーに接続して、Solrコンテナーにアクセスできるようにします。 クラスター内で作業するには、Solrを実行しているDockerコンテナーの1つに対して対話型のBashシェルを開始する必要があります。
MinikubeサーバーにSSHで接続するには:
1.以下のコマンドを実行して、 minikube ノードの status。
以下に示すように、出力はMinikubeノードが実行されていることを示しています。

2.次に、次のコマンドを実行して、Minikubeノードに割り当てられたIPアドレスを返します。
MinikubeノードにSSHで接続するために必要になるため、出力からIPアドレスを書き留めます(ステップ2)。

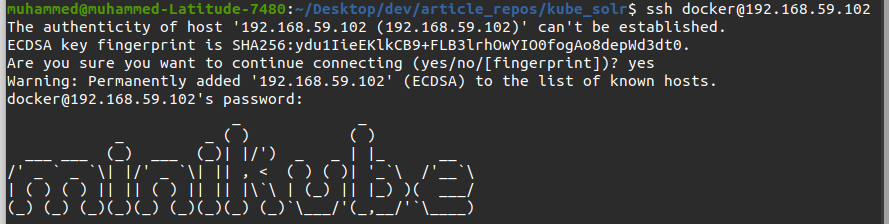
3.最後に、以下を実行します ssh MinikubeノードにSSHで接続するコマンド。 交換 192.168.59.102 手順2で書き留めたIPアドレスを使用します。
下の画像のようにプロンプトに入力します。 Minikubeノードのデフォルトのパスワードはtcuserで、パスワードプロンプトに入力します。
Solrコアの作成
Solrクラスターを管理するときは、Solrコマンドを実行する必要があるため、SolrインタラクティブBashシェルにアクセスする必要があります。 どのように? を作成することによって Solrコア。 Solrコアは、単一のインデックス、関連するトランザクションログ、および構成ファイルを参照します。
Solrコアを作成するには、Solrの1つを見つけて、Dockerコンテナー用の対話型Bashシェルを開始します。
1.以下を実行します docker ps Dockerコンテナのリストを取得するコマンド。
書き留める コンテナID Solrコンテナの1つです。 このチュートリアルでは、IDが 6f03c1576f47。

2.次に、 docker exec 以下のコマンドを実行して(exec)インタラクティブ(-it)。 bash 指定されたコンテナのシェル。 交換 6f03c1576f47 手順1でメモしたコンテナIDを使用します。 docker exec -it 6f03c1576f47 bash
docker exec -it 6f03c1576f47 bash以下では、プロンプトが変化するときに、コンテナのインタラクティブシェルにいることがわかります。 後でポート転送のために必要になるため、Solrコアを作成したポッド名を書き留めます。

3.インタラクティブシェルプロンプトで、以下のコマンドを実行して、 status Solrサーバーの
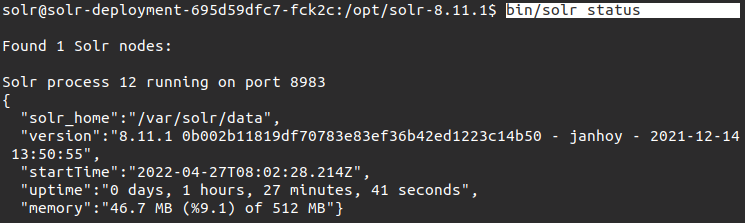
4.次に、以下を実行します bin/solr 次のコマンドを実行します。
- Solrコアを作成します(
create_core -c)名前付きtechproducts(名前は任意です)。 - 追加する configset と呼ばれる
sample_techproducts_configsの中に configsets ディレクトリ(-d server/solr/configsets/)。 構成セットには、Solrインストールで使用できる構成ファイルのセットが含まれています。
bin/solr create_core -c techproducts -d server/solr/configsets/sample_techproducts_configs/5.最後に、以下を実行します(bin/post)コマンド post のサンプルファイル example/exampledocs/ Solrが提供します。
このコマンドは、コンテナーをテストできるように、作成したSolrコアにサンプルファイルを追加します。
bin/post -c techproducts example/exampledocs/*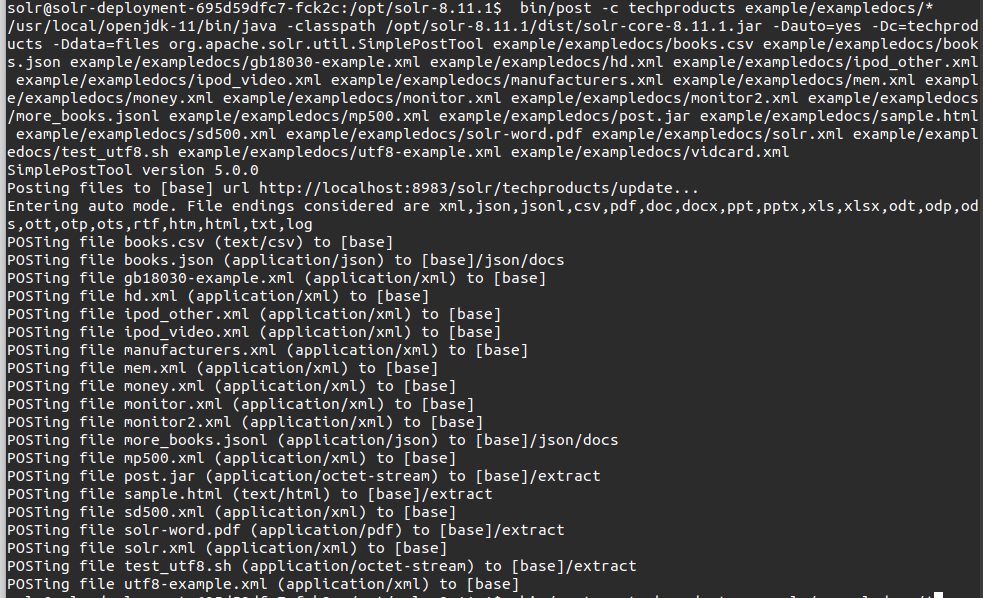
ApacheSolr管理者との対話
これで、KubernetesリソースとSolrCoreが正常にセットアップされました。 ただし、solr-serviceで作成したルートにはブラウザーからアクセスできないため、ポート転送を構成する必要があります。
Kubernetesで実行されるコンテナを設定して、ウェブブラウザで管理者にアクセスできるようにします。 管理者を機能させると、「Solrコアの作成」セクションの最後のステップで投稿したデータ/ファイルのクエリを簡単に作成できます。
1.別のターミナルを開き、次のコマンドを実行してポッドのリストを取得します。
Solrコアを作成したコンテナーを含むポッド名をコピーします。

2.次に、 kubectl port-forward ローカルポートを転送するには、以下を参照してください(28983)クラスターに(8983)。 交換 pod_name 手順1でメモしたポッド名を使用します。
このコマンドを使用すると、管理者にアクセスしてデータへのクエリを開始できます。
kubectl port-forward pod_name 28983:8983
3.お気に入りのWebブラウザーを開き、http:// localhost:28983/に移動します。
すべてがうまくいけば、下の画像のようなSolr管理ダッシュボードが表示されます。
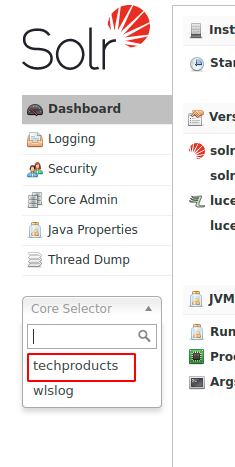
4. Solrダッシュボードで、をクリックします。 コアセレクト ドロップダウンして、Solrコアを選択します。
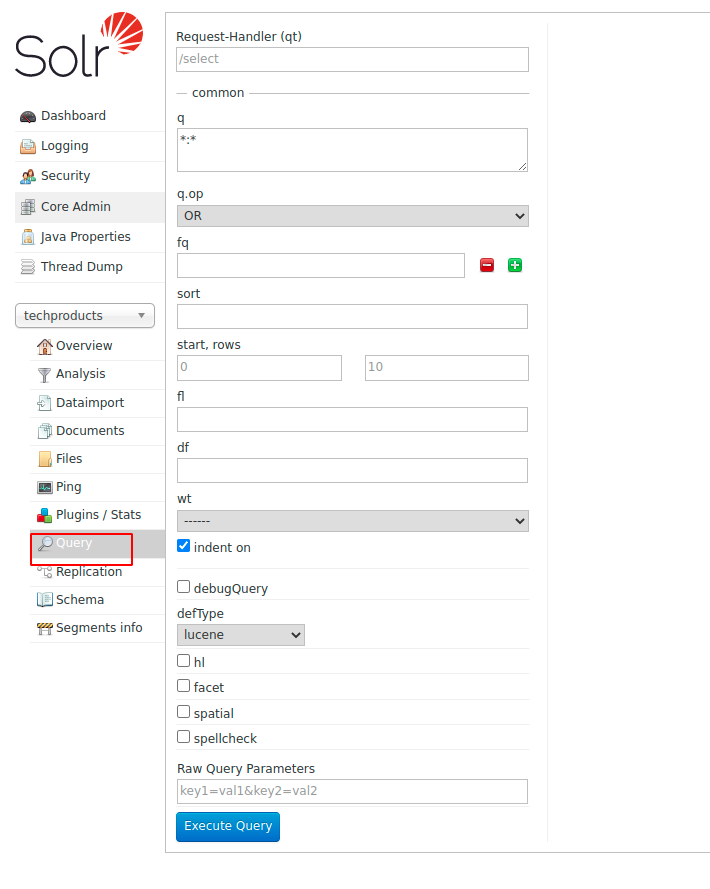
5. Solr Coreを選択したら、をクリックします。 クエリ メニュー。 新しいページが開き、データのクエリを構成できます。
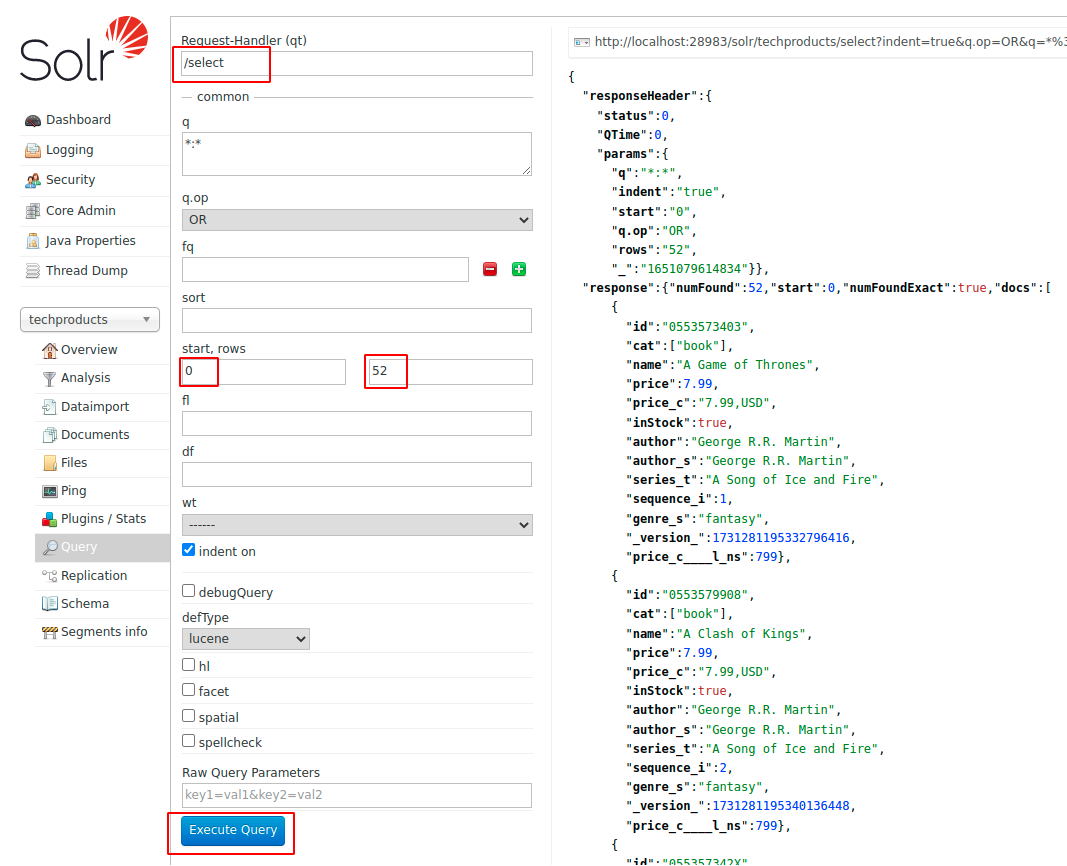
6.以下に示すように情報を入力し、をクリックします クエリを実行する ページの下部に、JSON形式で保存したすべてのドキュメントが表示されます。
- /選択する –すべてのファイルのコンテンツを取得するためのルート。
- 0 –最初の行を表します。
- 52 –最後の行を表します。
この時点で、他の操作を実行して、Solrの動作について詳しく知ることができます。
クラスターのスケーリング
クラスタの管理は、データのクエリだけにとどまりません。 アプリケーションで大量のトラフィックが発生し始めたと仮定すると、他のApache Solrチュートリアルで提案されているように、クラスターをスケーリングすることをお勧めします。 クラスタ内の特定のアプリケーションを処理するポッドの数を増やすことで、Kubernetesクラスタをスケーリングします。
クラスターをスケーリングするには、レプリカの数を増やします deploy.yaml ファイルを作成し、変更した構成を適用します。
1.を開きます deploy.yaml お好みのテキストエディタでファイルを作成し、の既存の値を置き換えます レプリカ から 3 に 6、以下に示すように。 ポッドレプリカの価値を高めることで、アプリケーションの高可用性が保証されます。

2.を実行します kubectl apply 以下のコマンドを使用して、展開に変更を適用します(deployment.yaml)。
kubectl apply -f deployment.yaml
3.最後に、 kubectl get 以下のコマンドを使用して、使用可能なすべてのポッドを表示します。
以下では、3つではなく6つのポッドが実行されていることがわかります。

結論
このチュートリアルでは、Solrインストールに含まれているサーブレットコンテナ内で全文検索サーバーを実行する方法を学習しました。 また、KubernetesとApache Solrを相互作用させて、クラスターを管理およびスケーリングする方法についても触れました。
新しく習得した知識をどのように適用するか知りたいですか? おそらく、アプリケーション検索を処理するマイクロサービスとしてSolrをアプリケーションに追加しますか?
The post Kubernetesを介した検索サーバーの作成 appeared first on Gamingsym Japan.