
SQLiteは、自己完結型でデプロイメントを必要としないトランザクション指向のSQLデータベースシステムを定義するフレームワークです。 SQLiteのコードベースは主流です。つまり、個人的または専門的なあらゆる目的に使用できます。 SQLiteは、おそらく世界中で最も広く使用されているデータベースであり、数え切れないほどの数のアプリケーションやいくつかの高度なイニシアチブが含まれています。
SQLiteは、統合デバイス用のSQLデータベースシステムです。 SQLiteには、他の多くのデータベースシステムのような個別のサーバーコンポーネントは含まれません。 SQLiteはデータを通常のデータベースファイルにネイティブに書き込みます。 単一のデータベースファイルは、多くのテーブル、インデックス、イニシエーター、および列を含むSQLデータベース全体で構成されます。 データベースファイルタイプのファイルタイプは多次元であるため、32ビットおよび64ビットオペレーティングシステム間でデータベースを簡単に複製できます。 SQLiteは、これらの属性のために広く使用されている統計ファイルシステムです。
SQLiteの「DISTINCT」用語は、「SELECT」コマンドのデータセットを評価し、重複するすべての値を削除して、取得されたエントリが「SELECT」クエリの有効なセットからのものであることを確認できます。 レコードが重複しているかどうかを判断する場合、SQLiteの「DISTINCT」という用語は、「SELECT」コマンドで提供された1つの列とデータのみを分析します。 SQLiteの「SELECT」クエリで単一の列に対して「DISTINCT」を宣言すると、「DISTINCT」クエリはその定義された列からのみ一意の結果を取得します。 SQLiteの「SELECT」コマンドで複数の列に「DISTINCT」クエリを適用できる場合、「DISTINCT」はこれらの各列の組み合わせを使用して重複データを評価できます。 NULL変数は、SQLiteでは冗長性と見なされます。 したがって、NULLエントリのある列で「DISTINCT」クエリを使用している場合、これはNULLデータを含む単一の行のみを保持します。
例
さまざまな例を使用して、SQLite DISTINCT用語、SELECTクエリによるSQLite DISTINCT、および特定のテーブルから一意の値を取得するためにいくつかの列で一意のSQLiteSELECTを使用する方法を発見します。
クエリを実行するには、コンパイラをインストールする必要があります。 ここにSQLiteソフトウェア用のBDブラウザをインストールしました。 まず、コンテキストメニューから「新しいデータベース」オプションを選択し、新しいデータベースを確立しました。 SQLiteデータベースファイルフォルダに配置されます。 クエリを実行して、新しいデータベースを作成します。 次に、特殊なクエリを使用して、テーブルを作成します。
テーブルの作成
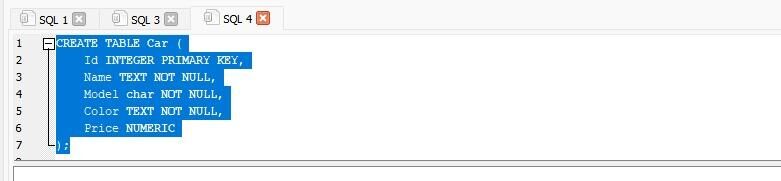
ここでは、「Car」のテーブルを作成し、その中のデータを指定します。 テーブル「Car」には、列「Id」、「Name」、「Model」、「Color」、および「Price」が含まれています。 列「Id」は整数データ型、「Name」と「Color」はテキストデータ型、「Model」は文字データ型、「Price」は数値データ型です。
|
1 |
作成 テーブル 車 ((
Id 整数 主要な 鍵、 )。; |
次の出力は、「CREATE」のクエリが正常に実行されたことを示しています。
データの挿入
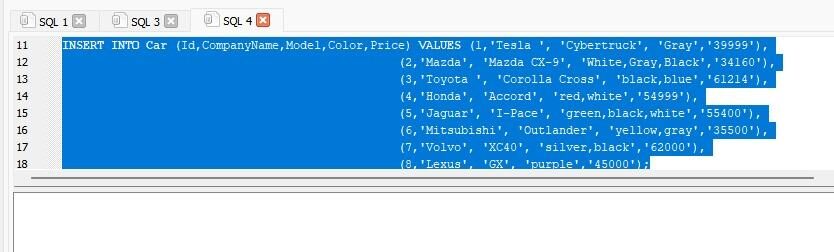
ここで、データをテーブル「Car」に挿入したいので、「INSERT」のクエリを実行します。
|
1 |
入れる の中へ 車 ((Id、会社名、モデル、色、価格)。 値 ((1、「テスラ」、 「サイバートラック」、 ‘グレー’、‘39999’)。、
((2、「マツダ」、 「マツダCX-9」、 「白、灰色、黒」、‘34160’)。、 ((3、「トヨタ」、 「カローラクロス」、 ‘ブラックブルー’、‘61214’)。、 ((4、「ホンダ」、 ‘アコード’、 「赤、白」、‘54999’)。、 ((5、‘ジャガー’、 「I-Pace」、 「緑、黒、白」、‘55400’)。、 ((6、「三菱」、 「アウトランダー」、 「黄色、灰色」、‘35500’)。、 ((7、「ボルボ」、 「XC40」、 「シルバー、ブラック」、「62000」)。、 ((8、「レクサス」、 「GX」、 ‘紫の’、「45000」)。; |
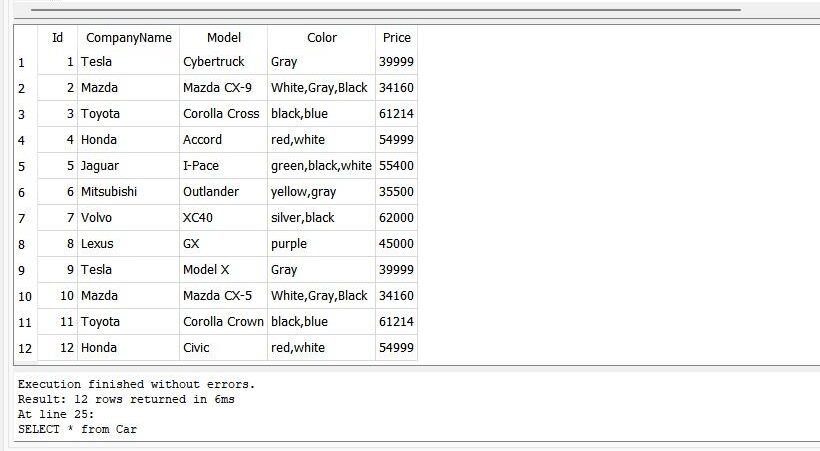
さまざまな車のID、CompanyName、Model、Color、Priceなどのデータをテーブルに正常に挿入しました。

「SELECT」クエリを使用する
「SELECT」クエリを使用して、テーブルのデータ全体を取得できます。

前のクエリを実行した後、12台の車のすべてのデータを取得できます。
1つの列で「SELECTDISTINCT」クエリを使用する
SQLiteの「DISTINCT」という用語は、「SELECT」クエリと組み合わせて使用され、重複するすべてのエントリを削除し、個別の値のみを取得します。 たぶん、テーブルにいくつかの重複したエントリがある場合があります。 これらのデータを取得するときは、データを複製するよりも、個別のアイテムを取得する方が理にかなっています。
|
1 |
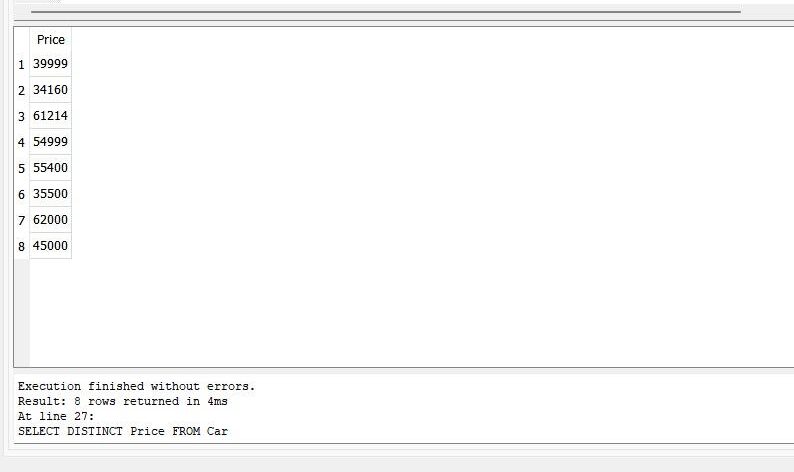
>> 選択する 明確 価格 から 車 |

「Car」の表には12台の車のデータがあります。 ただし、「Price」列に「SELECT」クエリとともに「DISTINCT」を適用すると、出力で車の一意の価格を取得できます。
複数の列で「SELECTDISTINCT」クエリを使用する
「DISTINCT」コマンドは複数の列に適用できます。 ここでは、テーブルの「CompanyName」列と「Price」列の重複する値を削除します。 そこで、「DISTINCT」を活用しています。
|
1 |
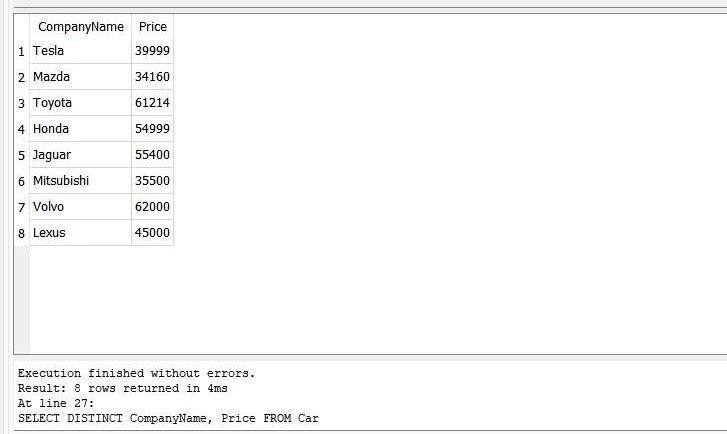
>> 選択する 明確 会社名、 価格 から 車 |

クエリを実行すると、結果には「price」の一意の値と「CompanyName」の一意の名前が表示されます。
この場合、テーブル「Car」の列「CompanyName」と「Price」に「DISTINCT」クエリを使用します。 ただし、「WHERE」句を使用してクエリで「CompanyName」を指定します。
|
1 |
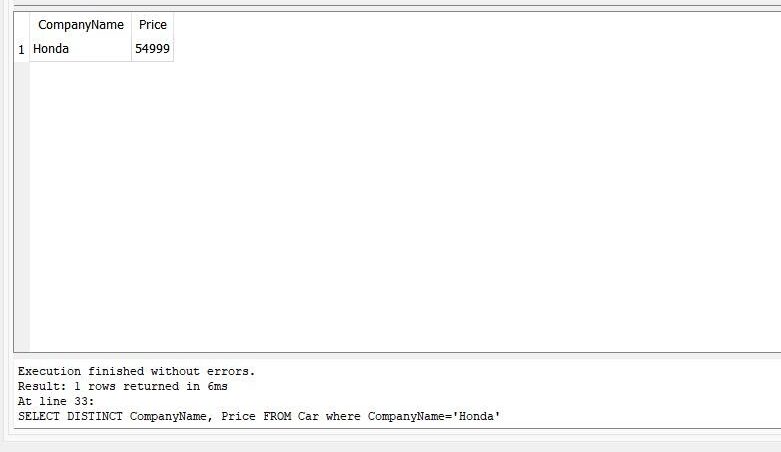
>> 選択する 明確 会社名、 価格 から 車 どこ 会社名=「ホンダ」 |

次の図に出力を示します。
ここでは、「SELECTDISTINCT」クエリと「WHERE」句を使用します。 このクエリでは、「WHERE」句で条件を指定しました。これは、車の価格が50000未満でなければならないことを示しています。
|
1 |
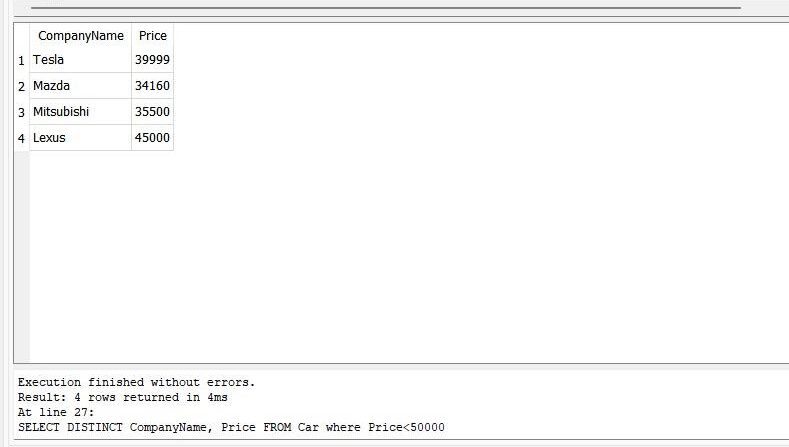
>> 選択する 明確 会社名、 価格 から 車 どこ 価格<<50000 |

クエリは4行を返します。 「CompanyName」列と「Price」列に重複する行がいくつかあります。 「DISTINCT」ステートメントを使用して、これらの重複する値を削除します。
「SELECTDISTINCT」および「BETWEEN」句を使用します
「DISTINCT」句は、「SELECT」ワードの直後に適用されます。 次に、この例では「DISTINCT」句と「BETWEEN」句を一緒に使用します。 「BETWEEN」句は、車の価格が20000から50000の間になるという条件を示しています。
|
1 |
>> 選択する 明確 会社名、 色、 価格 から 車 どこ 価格 の間に 20000 と 50000 |

結果は、価格が20000から50000の間にある車の「CompanyName」と「Color」を示しています。

結論
この記事では、SQLiteの「SELECTDISTINCT」ステートメントを使用して、データセットから重複するエントリを削除する方法について説明しました。 SELECTクエリでは、「DISTINCT」コマンドはオプション機能です。 「DISTINCT」ステートメントで単一の式が指定されている場合、クエリは式の個別の値を提供します。 「DISTINCT」ステートメントに複数の式が含まれている場合は常に、クエリは上記の式に特定のセットを提供します。 SQLiteの「DISTINCT」コマンドはNULL値を回避しません。 その結果、SQLクエリで「DISTINCT」コマンドを使用すると、結果にNULLが個別の要素として表示されます。
The post SQLiteSELECTDISTINCTステートメント appeared first on Gamingsym Japan.