
SQLにはデータの重複を防ぐための制約がありますが、レコードが重複している既存のデータベースに遭遇する可能性があります。
このチュートリアルを使用して、データベース内の重複行を識別する方法を学びます。
SQLの重複検索
重複する行を見つけるために使用できる最初の方法は、カウント関数です。
次のようなサンプルデータを含むテーブルがあるとします。
作成 テーブル 製品((
idシリアル、
商品名 VARCHAR((255)。、
量 INT
)。;
入れる の中へ 製品((商品名、 量)。
値 ((‘りんご’、 100)。、
((‘オレンジ’、 120)。、
((‘りんご’、 100)。、
((‘バナナ’、 300)。、
((‘オレンジ’、 100)。、
((‘バナナ’、 300)。;
上記のクエリは、次のようにテーブルを返す必要があります。
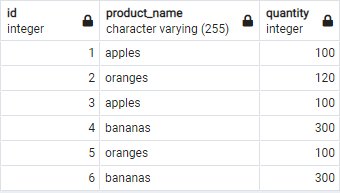
重複レコードをフィルタリングするには、次のようにクエリを使用できます。
選択する 商品名、
量
から 製品
グループ に 商品名、
量
持っている カウント((ID)。 >> 1;
上記のクエリでは、group byおよびcount関数を使用して、重複するレコードを検索します。 これにより、次のような出力が返されます。
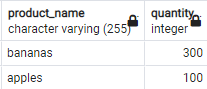
上記のクエリは、同じ値を持つ行のグループを作成することで機能します。 これは、groupby句を使用して実行されます。 次に、カウントが1より大きいグループを見つけます。これは、グループに重複があることを意味します。
終了
この記事では、groupbyおよびcount句を使用してSQLで重複レコードを見つける方法を発見しました。
読んでくれてありがとう!!
The post SQL重複行の検索 appeared first on Gamingsym Japan.