
この記事では、Pythonでのパンダローリングgroupby関数について説明します。 ここでは、Pandasのローリングgroupby関数と、Pythonコードでその関数を使用する方法について学習するのに役立ついくつかの便利な例を示します。 それでは、ローリング関数の定義から始めましょう。
パンダローリングとは何ですか?
Pandasはいくつかの便利な関数を提供し、rolling()は、データに対して複雑な計算を実行できる非常に優れた関数の1つです。 Rolling()関数は、指定されたオブジェクト系列の入力データに対するローリングウィンドウ計算を提供します。 ローリングウィンドウの概念は、主に時系列データまたは信号処理で使用されます。
言い換えると、ウィンドウサイズ「w」を一度に「t」とし、それにいくつかの数学演算を適用したとしましょう。 ウィンドウの「w」サイズは、すべての「w」値が重み付けされている「t」での「w」連続値を意味します。
ローリングウィンドウとは何ですか?
ローリングウィンドウの基本的な概念は、提供された日付からローリングウィンドウシフトまでのデータを計算することです。 たとえば、従業員が6か月のローリングウィンドウを使用している場合、毎年1月1日に給与を受け取り、毎年7月1日に別の給与を受け取ることを意味します。 単純なローリングウィンドウは最初の日付を基準にしており、指定されたローリングウィンドウ時間で自動的に転送されます。この例では、6か月のローリングウィンドウです。
Pandas Rolling()関数はDataFrameとどのように連携しますか?
Python Pandasのrolling()関数は、ローリングウィンドウカウントの要素を提供します。 Pythonでのローリングウィンドウの考え方は、ローリングウィンドウの一般的な考え方と同じです。 簡単に言うと、ユーザーは重み付きウィンドウサイズ「w」を一度に指定し、それにいくつかの数学演算を実行します。
Pandas Rolling Groupby関数の構文は何ですか?
以下に、groupby関数をローリングするPandasの構文を示します。

ご覧のとおり、rolling()関数は8つのパラメーターを取ります。 windowSize、MinPeriod、frequency、Center、WinType、on、axis、およびclosed。
‘windowSize’パラメーターは、移動ウィンドウのサイズを定義します。これは、簡単に言うと、計算を実行する必要がある回数であり、デフォルトではその値は1です。’MinPeriod’パラメーターは、定義されたで必要な観測の最小数を定義します。窓。 「頻度」パラメーターは、統計計算を実行する前のデータの頻度を定義します。 ‘Center’パラメータは、ウィンドウの中央にあるラベルを定義します。
‘WinType’パラメータは、ウィンドウのタイプを定義します。 ‘on’パラメーターは、ローリングウィンドウの計算を実行する必要があるDataFrameのインデックスではなく、列を定義します。 「closed」パラメーターは、「どちらでもない」、「左」、「右」、または「両方」の端点で閉じる必要がある間隔を定義します。
そして最後に、’axis’パラメーターは、整数または文字列形式で軸の値を提供します。デフォルトでは0です。次に、例に進んで、Pythonコードにrolling()関数を含める方法を学びましょう。 Pythonのパンダのrolling()関数がDataFrameでどのように機能するか。
例1
それでは、rolling()関数で使用する必要のある単純なDataFrameの作成から始めましょう。 データフレームには、10、18、50、70、およびnp.nanの5つの値が定義されています。 その後、rolling()関数を呼び出して、ウィンドウサイズ3を指定します。これが、groupby関数をローリングするpandasのコードです。
輸入 パンダ なので pd
輸入 numpy なので np
df = pd。DataFrame(({{「Z」: [10, 18, 50, 70, np.nan]})。
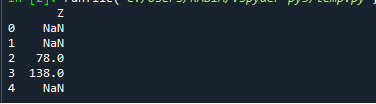
印刷((df。圧延((3)。。和(()。)。

以下は、上記のコードの出力です。 最初の2つの値はnanであり、3番目の値は前の3つの値10、18、および50の合計である78であることに注意してください。ウィンドウサイズ3を指定したので、ローリング関数は3つのウィンドウの後に計算機を実行しました。 4番目の値138は、18、50、および70の3つの前の値の合計です。最後の値は再びnanであることに注意してください。これは、ウィンドウサイズの有効期限が切れているなどの理由ではなく、5番目の入力値がナン。 したがって、nanに追加されるものはすべてnanになります。
例2
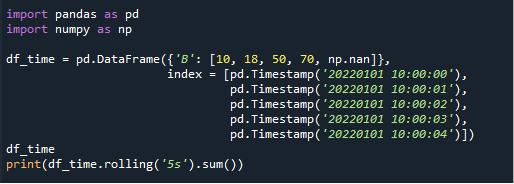
Rolling()関数の簡単な例を見てきました。次に、タイムスタンプタイプのDataFrameを作成して、rolling()関数が日付/時刻タイプのデータでどのように機能するかを理解しましょう。 ここでは、前の例で作成したものと同じDataFrameを使用しますが、ここで、各列のタイムスタンプ値を指定するインデックス列を追加します。 以下のコードの追加のインデックス列を参照してください。
輸入 numpy なので np
df_time = pd。DataFrame(({{「B」: [10, 18, 50, 70, np.nan]}、
索引 = [pd.Timestamp(‘20220101 10:00:00’),
pd.Timestamp(‘20220101 10:00:01’),
pd.Timestamp(‘20220101 10:00:02’),
pd.Timestamp(‘20220101 10:00:03’),
pd.Timestamp(‘20220101 10:00:04’)])。
df_time
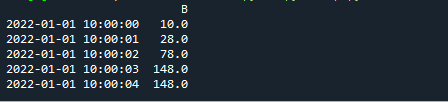
印刷((df_time。圧延((「5s」)。。和(()。)。
タイムスタンプデータのrolling()関数を実行すると、次の出力が得られます。
例3
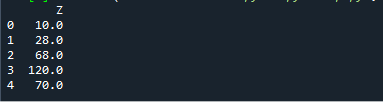
この例では、rolling()関数にMinPeriodを指定する方法を学習するのに役立ちます。 上で説明したように、rolling()関数のMinPeriodパラメーターは、数学演算を実行するために必要な観測の最小数を定義します。 ここでも、ローリングウィンドウサイズ3とMinPeriod1で合計を計算しています。以下のコードを参照してください。
輸入 パンダ なので pd
輸入 numpy なので np
df = pd。DataFrame(({{「Z」: [10, 18, 50, 70, np.nan]})。
印刷((df。圧延((2、 min_periods=1)。。和(()。)。

上記のコードの出力は次のとおりです。
結論
この記事では、Pythonでのrolling()関数の使用方法を示しました。 簡単な例を使用して、rolling()関数がDataFrameでどのように機能するかを観察しました。 上記のコードはすべて、Pythonの任意のコンパイラに実装できます。
The post パンダローリンググループビー appeared first on Gamingsym Japan.