
pandas describe()関数を使用すると、PandasDataFrame内のデータの統計要約を取得できます。 この関数は、統計平均、標準偏差、最小値と最大値など、データに関する統計情報を返します。
関数の構文
関数の構文は次のとおりです。
|
1 |
DataFrame。説明((パーセンタイル=なし、 含む=なし、 除外する=なし、 datetime_is_numeric=間違い)。 |
関数パラメーター
この関数は、次のパラメーターを受け入れます。
- パーセンタイル –DataFrame内のデータの特定のパーセンタイルを取得できます。 パーセンタイル値の範囲は0から1です。
- 含む – Noneおよびallを含む、受け入れられた値を使用して結果セットに含めるデータ型のリストを指定します。
- 除外する –結果セットで除外するデータ型のリスト。
- datetime_is_numeric –関数が日時オブジェクトを数値として処理できるようにします。
関数の戻り値
この関数は、各行が列の統計プロパティのタイプを保持するDataFrameを返します。
例
Pandasでのdescribe()関数の主な使用法を示す以下の例を検討してください。
|
1 |
輸入 パンダ なので pd |
上記の例では、パンダライブラリをインポートすることから始めます。 次に、単純なDataFrameを作成し、describe()メソッドを呼び出します。
上記のコードは、DataFrameに関する基本的な情報の要約を返す必要があります。 出力例は次のとおりです。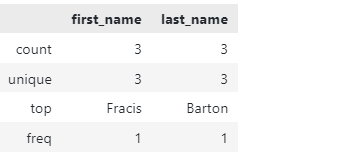
関数が値の数、一意の数、最高値などの基本的な統計情報を返す方法に注意してください。
例2
Pandasシリーズの統計要約を返す以下の例を考えてみましょう。
|
1 |
s = pd。シリーズ(([10,20,30])。 |
この例では、関数は次のように出力を返す必要があります。
この場合、関数は、標準の平均、25、50、75パーセンタイル、および系列の最大値などの基本的な要約情報を返します。
例3
Pandas DataFrameの特定の列を説明するには、次の構文を使用します。
|
1 |
DataFrame。column_name。説明(()。 |
例4
結果から特定のデータ型を除外するには、次の構文を使用します。
|
1 |
df。説明((除外する=[np.datatype])。 |
例5
データ型に関係なく、DataFrameのすべての列を記述するには、次のコードを実行します。
|
1 |
df。説明((含む=‘全て’)。 |
結論
この記事では、Pandasでdescribe()関数を使用する方法について説明しました。
The post パンダは説明します appeared first on Gamingsym Japan.