
この記事では、C#プログラミング言語でのコレクションの名前空間について説明します。 コレクション名前空間は通常、データの保存、改良、操作、さらには並べ替えによってデータを管理するために使用されます。 コレクション名前空間には、データを格納および改良するためのさまざまな関数とメソッドを使用してデータを変換およびソートできるいくつかのクラスがあります。 コレクション名前空間は、これらのクラスを呼び出し、プログラミング中にデータを処理するためにそれらの機能を利用するために使用されます。
Collections名前空間のクラス:
C#プログラムでSystem.Collections名前空間を使用すると、次のクラスのリストにアクセスして、データを操作および蓄積できます。
- 配列リスト
- スタック
- 列
- ソート済みリスト
- ハッシュ表
これらのクラスはすべて、データ処理に関していくつかの類似点といくつかの相違点があります。 これらはすべて、データの保存方法とデータの表現方法がやや独特です。 これについて1つずつ説明し、Ubuntu20.04環境にも実装します。
C#プログラミング言語の「コレクション」名前空間の配列リストクラス:
配列リストは、データを並べ替えてメモリに動的に割り当てることができるため、データを効率的に保存する方法です。 各要素の個別のインデックス番号からアクセスできるため、配列リスト内のデータを処理および検索するために非常にアクセスしやすくなっています。 配列リストのサイズは具体的であり、ユーザーのニーズに応じて拡張できるため、不確実な状況で非常に適しています。 次に、system.collection名前空間を使用してC#プログラミング言語で単純な配列リストを実装し、データの格納方法をよりよく理解します。

上記のC#プログラムでは、最初にSystem.Collection名前空間を初期化して、ArrayListクラスにアクセスできるようにしました。 次に、クラスの関数にアクセスできるArrayListクラスのオブジェクトを作成しました。 次に、いくつかの整数変数を初期化し、それらに値を割り当てました。 配列リストクラスで作成したオブジェクトは、整数変数を配列リストに追加するAdd()関数を呼び出すために使用されます。 最後に、for eachループを使用して、整数変数が配列リストにどのように保存されるかを確認します。

これは、配列リストに追加された番号の順序であり、リストが具体的であり、後で拡張することもできることがわかります。
C#プログラミング言語のスタックコレクションクラス:
スタックは、後入先出法を意味するLIFOメソッドを使用してデータが格納されるデータ収集クラスです。 スタックコレクションクラスは、最後に保存されたデータに最初にアクセスし、それを変更または削除する必要がある場合に使用されます。 Push()およびPop()と呼ばれるスタックの要素を追加および削除するための特別な関数があります。 これらの関数は両方とも、LIFOメソッドで実行されるときに、スタックの最後に更新されたインデックスで機能します。 Ubuntu20.04環境でのスタックデータ収集メソッドの例を実装します。
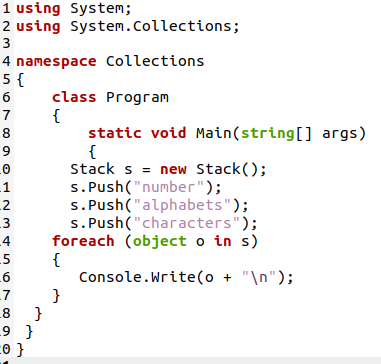
このプログラムでStackクラスのオブジェクトを作成して、スタッククラスに存在する関数にアクセスできるようにします。 次に、オブジェクトがPush()関数にアクセスして、スタックにデータを追加します。 次に、スタックリストを印刷して、データがどのように保存されているかを確認しました。

出力が示すように、最後に更新されたデータが最初に表示され、スタックデータ収集のLIFO方法が確認されます。
C#プログラミング言語の「Collections」名前空間のキュークラス:
データは、保存および更新された順序で保存されます。 このクラスのデータを追加および削除するための特別な関数は、Enqueue()およびDequeue()です。 キューの現在のインデックスは、常にキューに保存された最初のデータです。 Peek()は、キューの最初に追加されたデータを表示するQueueクラスの特別な関数でもあります。 キューの概念をC#プログラムに実装し、スタックとキューの違いを調べるために追加されたデータのリストを表示します。
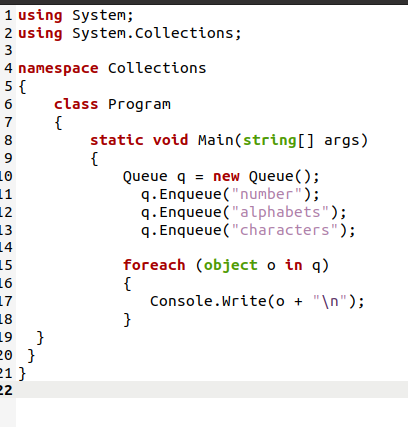
このコードでは、System.Collection名前空間を呼び出して、データを格納するためのQueueクラスにアクセスします。 Queueクラスのオブジェクトを作成し、それを使用してEnqueue()関数を使用してデータをキューに追加しました。 次に、foreachループを使用してキューを出力しました。

出力が示すように、データは、スタックとは逆の場合と比較して、保存されたのと同じ順序で表示されました。
C#プログラミング言語の「コレクション」名前空間のソート済みリストクラス:
ソートされたリストは、データがキーと値の関係でペアで保存されるデータ収集タイプです。 値は、キーに基づいて昇順で並べ替えられます。 ソートされたリストには、いつでもリストのインデックスから簡単にアクセスできます。 Add()関数とremove()関数は、それぞれリストからデータを追加および削除するために使用されます。 Clear()関数は、リストからすべてのデータをクリアするためにも使用されます。

このC#プログラムにソート済みリストを実装しました。 まず、Collections名前空間を呼び出してから、Sortedリストクラスのオブジェクトを作成して、その関数にアクセスできるようにしました。 次に、オブジェクトはデータをキーと値のペア形式で保存しました。 最初の式がキーで、2番目の式が値です。 データはディクショナリエントリに保存され、for-eachループを使用して、並べ替えられたリストのデータを出力します。 上記のプログラムをコンパイルして実行すると、以下のスニペットに示すような出力が得られます。
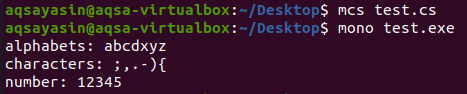
並べ替えられたリストのデータは、キー式のアルファベットの昇順で保存されていることがわかります。
C#プログラミング言語の「コレクション」名前空間のハッシュテーブル:
ハッシュテーブルは、並べ替えられたリストのようにデータをペアで格納するデータのコレクションです。 ハッシュテーブルには、テーブルを蓄積するための一連のコードがあります。 したがって、ユーザーとして、常にテーブルを作成する必要はありません。 ハッシュテーブルコレクションを呼び出すだけで、テーブルが自動的に作成されます。 ハッシュテーブルコレクションには、データを追加、削除、または操作するために分類されたいくつかのメソッドがあります。 それらのいくつかは、Add()、Clear()、ContainsKey()、ContainsValue()です。 この概念をUbuntu20.04環境に実装します。
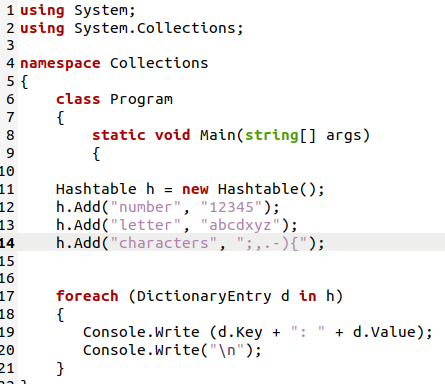
このC#プログラムでは、最初にSystem.Collection名前空間を呼び出してHashテーブルにアクセスし、次にこのオブジェクトを作成して、使用するすべてのプロパティとデータ処理メソッドを呼び出しました。 そのオブジェクトで、Add()関数を使用して、キーと値のペアの形式でデータをハッシュテーブルに追加しました。 ペアのデータはディクショナリエントリに保存されるため、これをfor eachループで使用して、テーブルの内容を出力します。
これは、上記の出力画面に示されているように、ハッシュテーブルがキーと値の形式でデータ自体を保存する方法です。
結論:
この記事では、C#プログラミング言語でのCollections名前空間について説明しました。 collections名前空間には、さまざまな方法とメソッドでデータを格納および蓄積して並べ替える一連のデータ収集クラスがあります。 日常のプログラミングで使用するこれらのクラスのいくつかについて説明し、Ubuntu20.04環境にも実装しました。
The post C#コレクション appeared first on Gamingsym Japan.