
この記事は、PandasDataFrameで文字列を検索するために使用できるさまざまな方法を理解するのに役立ちます。
パンダにはメソッドが含まれています
Pandasは、サブストリングがPandasシリーズまたはDataFrameに含まれているかどうかを検索できるcontains()関数を提供します。
この関数は、リテラル文字列または正規表現パターンを受け入れ、既存のデータと照合します。
関数の構文は次のとおりです。
|
1 |
シリーズ。str。含む((パターン、 場合=真実、 フラグ=0、 na=なし、 正規表現=真実)。 |
関数パラメーターは次のように表されます。
- パターン –検索する文字シーケンスまたは正規表現パターンを指します。
- 場合 –関数が大文字と小文字の区別に従うかどうかを指定します。
- フラグ –RegExモジュールに渡すフラグを指定します。
- na –不足している値を埋めます。
- 正規表現 – Trueの場合、入力パターンを正規表現として扱います。
戻り値
この関数は、パターン/サブストリングがDataFrameまたはシリーズで見つかったかどうかを示すブール値のシリーズまたはインデックスを返します。
例
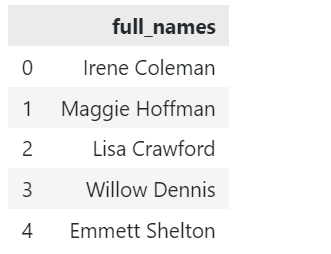
以下に示すサンプルDataFrameがあるとします。
|
1 |
#パンダをインポート
輸入 パンダ なので pd df = pd。DataFrame(({{「full_names」: [‘Irene Coleman’, ‘Maggie Hoffman’, ‘Lisa Crawford’, ‘Willow Dennis’,‘Emmett Shelton’]})。 |
文字列を検索する
文字列を検索するには、次のようにパターンパラメータとして部分文字列を渡すことができます。
|
1 |
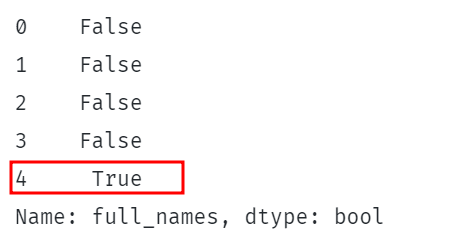
印刷((df。full_names。str。含む((「シェルトン」)。)。 |
上記のコードは、文字列’Shelton’がDataFrameのfull_names列に含まれているかどうかを確認します。
これにより、文字列が指定された列の各行にあるかどうかを示す一連のブール値が返されます。
例は次のとおりです。
実際の値を取得するには、contains()メソッドの結果をデータフレームのインデックスとして渡すことができます。
|
1 |
印刷((df[df.full_names.str.contains(‘Shelton’)])。 |
上記は戻るはずです:
|
1 |
full_names |
大文字と小文字を区別する検索
検索で大文字と小文字の区別が重要な場合は、次のように大文字と小文字を区別してTrueに設定できます。
|
1 |
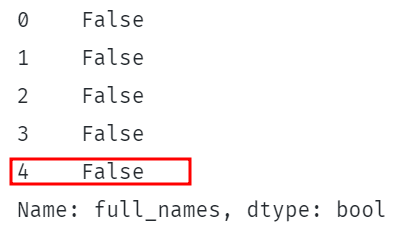
印刷((df。full_names。str。含む((「シェルトン」、 場合=真実)。)。 |
上記の例では、大文字と小文字を区別する検索を有効にするために、大文字と小文字を区別するパラメーターをTrueに設定しています。
小文字の文字列「shelton」を検索するため、関数は大文字の一致を無視してfalseを返す必要があります。
正規表現検索
正規表現パターンを使用して検索することもできます。 簡単な例を次に示します。
|
1 |
印刷((df。full_names。str。含む((‘wi | em’、 場合=間違い、 正規表現=真実)。)。 |
上記のコードでパターン「wi」または「em」に一致する文字列を検索します。 大文字と小文字の区別を無視して、大文字と小文字のパラメータをfalseに設定していることに注意してください。
上記のコードは次のようになります。

閉鎖
この記事では、contains()メソッドを使用してPandasDataFrameでサブストリングを検索する方法について説明しました。 詳細については、ドキュメントを確認してください。
The post パンダで文字列を検索 appeared first on Gamingsym Japan.