
過去5年間で、データサイエンス業界は爆発的に拡大し、データサイエンスの仕事は豊富で、高収入です。 しかし、データサイエンスを始めるのは難しい場合があります。 最大の障害の1つは、コンピューターに適切なツールと環境をセットアップすることです。 ええと、インストール方法がわからない限りではありません アナコンダ そしてそれをデータサイエンスに使用する方法。
Anacondaは、強力なデータサイエンスプラットフォームであり、データ分析、モデリング、および視覚化を開始するための優れた方法です。 このチュートリアルでは、Ubuntu LinuxにAnacondaをインストールする手順と、いくつかの基本的なデータ操作および視覚化タスクについて説明します。
準備? LinuxでAnacondaを使用してデータサイエンスを開始する方法を学ぶために読んでください!
前提条件
このチュートリアルは、実践的なデモンストレーションになります。 フォローしたい場合は、少なくとも4GBのRAMと5GBの空きディスク容量を備えたUbuntuLinuxマシンがあることを確認してください。
Anacondaのインストールに必要な最小ディスク容量は5GBですが、本格的なデータサイエンス作業を実行するには、より多くの空き容量が必要になります。 データセットをダウンロードして保存する必要があるため、データサイエンスに取り組むには多くのディスクスペースが必要です。 データサイエンスに取り組むには、マシンに50GBの空き容量があれば十分です。
AnacondaインストーラーBashスクリプトのダウンロード
データサイエンスに不慣れな方でも、経験豊富な専門家でも、Anacondaはデータ分析とモデリングのニーズに最適なプラットフォームです。 ただし、最初に、Anacondaをマシンにインストールする必要があります。
Anacondaをインストールするには、インストーラーのBashスクリプトをからダウンロードする必要があります。 アナコンダのウェブサイト。 執筆時点では、最新バージョンはAnaconda3-2021.11-Linux-x86_64.shです。
1.ターミナルを開き、以下のコマンドを実行して、AnacondaのインストーラーBashスクリプトをダウンロードして保存します。 / tmp ディレクトリ。
cd /tmp
curl -O https://repo.anaconda.com/archive/Anaconda3-2021.11-Linux-x86_64.sh2.次に、以下のsha256sumコマンドを実行して、ダウンロードしたファイル(Anaconda3-2021.11-Linux-x86_64.sh)のSHA-256暗号化ハッシュを生成します。 このコマンドは、MD5またはSHA256を使用してインストーラーのBashスクリプトの整合性を検証する方法を提供します。
インターネットからファイルをダウンロードすると、転送中にファイルが改ざんされたり破損したりするリスクが常に伴います。 インストーラーのBashスクリプトの整合性を検証することは、Anacondaが最初に公開したファイルの同一のコピーを受け取ったことを確認するために重要です。
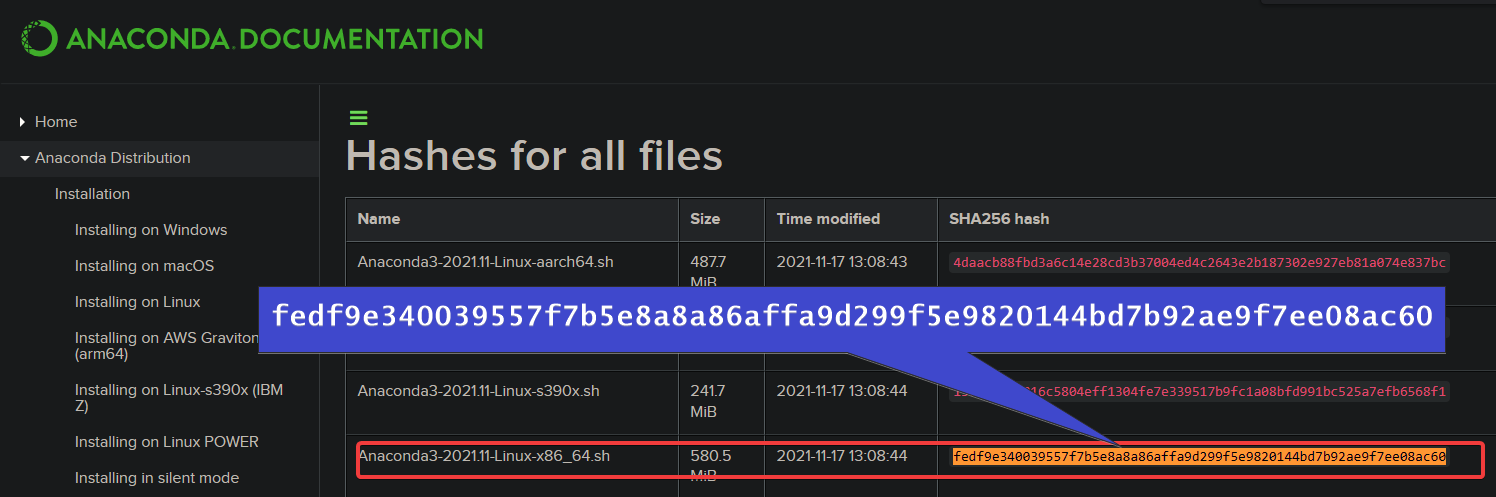
sha256sum Anaconda3-2021.11-Linux-x86_64.shファイルのハッシュを書き留めて、AnacondaのWebサイトで入手できるものと比較します(ステップ3)。

3.最後に、お気に入りのWebブラウザーを開き、次の場所に移動します。 アナコンダのハッシュリスト。
ダウンロードしたインストーラーBashスクリプトの名前(Anaconda3-2021.11-Linux-x86_64.sh)を探します。 見つかったら、手順2でメモしたハッシュがAnacondaのWebサイトにリストされているハッシュと一致することを確認します。
ハッシュが一致しない場合は、手順1〜3を繰り返して、ハッシュを再確認します。
UbuntuにAnacondaをインストールする
Bashスクリプトをダウンロードし、その整合性を確認したので、Anacondaをインストールする準備が整いました。 インストーラーのBashスクリプトには、必要なすべてのインストールコマンドが含まれているため、実行するだけで済みます。
1.次のコマンドを実行して、Anacondaをマシンにインストールします。 Anaconda3-2021.11-Linux-x86_64.shを、ダウンロードしたBashスクリプトファイルの名前に置き換えてください。
シェルに関係なく、bashコマンドを含める必要があることに注意してください。
bash Anaconda3-2021.11-Linux-x86_64.sh2. Bashスクリプトを実行した後、Enterキーを押して、プロンプトが表示されたらエンドユーザー使用許諾契約書(EULA)を表示します。 Enterキーを押し続けて、EULAの最後まで読みます。
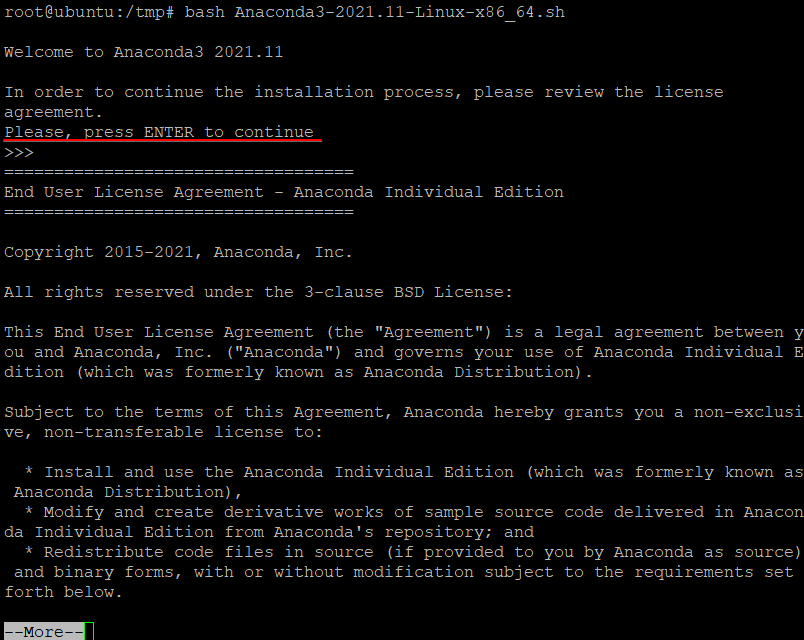
3. EULAを読んだ後、以下に示すように、yesと入力し、Enterキーを押してライセンス条項に同意します。

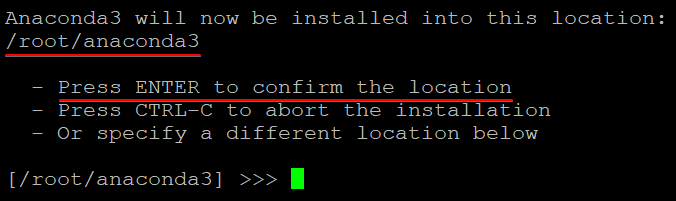
4.ここで、Enterキーを押して、Anacondaのデフォルトのインストール場所を受け入れます。 任意の場所を選択できますが、アクセスしやすいように、ホームフォルダ内のディレクトリを選択することをお勧めします。
5.「はい」と入力し、Anaconda3を初期化するように求められたらEnterキーを押します。 このcondainitコマンドは、マシンにログインするたびに端末からcondaコマンドを使用できるようにします。
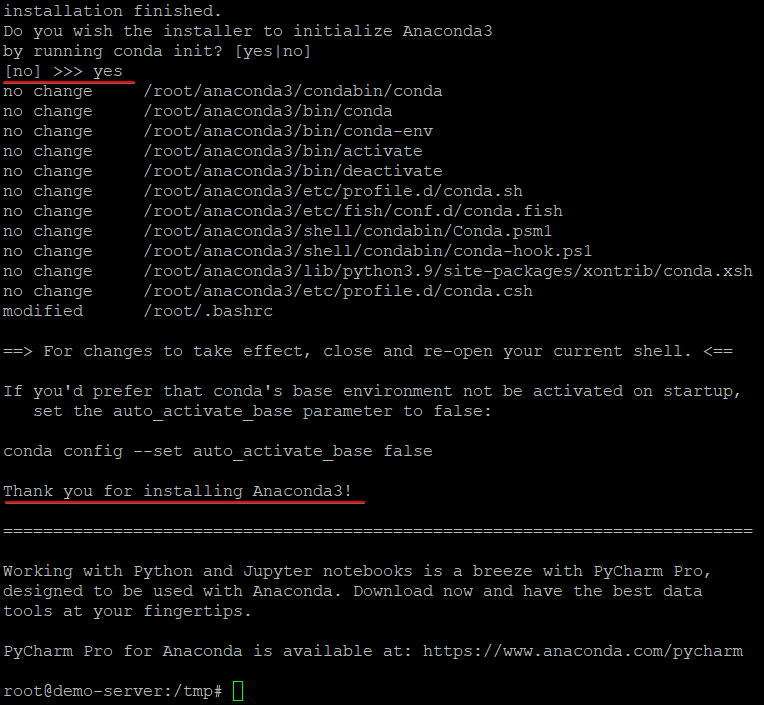
6.次に、以下のコマンドを実行して、変更をシェル環境に適用します。
以下に示すように、現在のシェルがベースに変更されます。これは、Anaconda3が正常にインストールされたことを示します。 baseは、データサイエンスに必要なすべてのコアPythonライブラリとツールを提供するAnacondaのデフォルトのシェル環境です。
基本シェル環境には、conda、anaconda prompt、JupyterNotebookなどの強力なコマンドラインツールが含まれています。

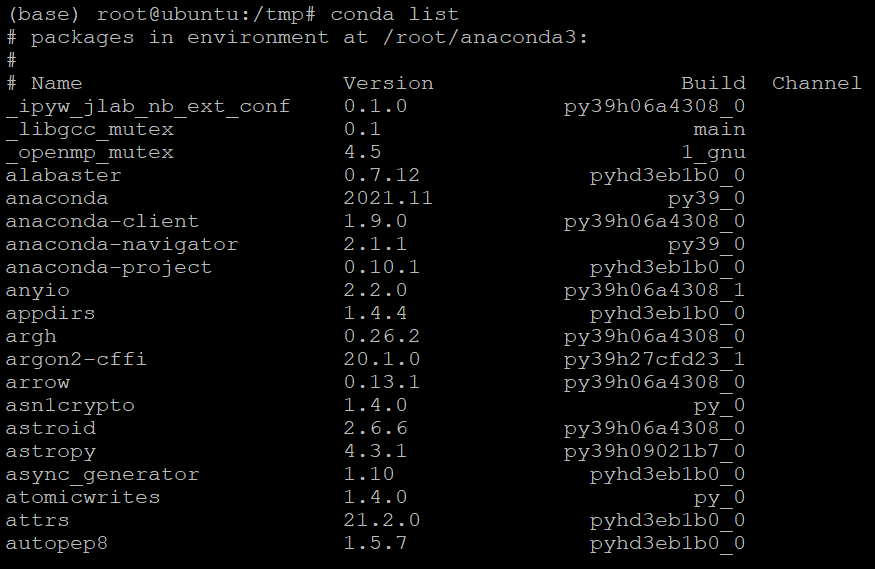
7.以下を実行します コンダリスト Anacondaが正しくインストールされていることを確認するコマンド。
以下に示すように、現在基本環境の一部として含まれているすべてのパッケージとバージョンのリストが表示されます。
8.最後に、以下のconda deactivateコマンドを実行して、anacondaセッションを閉じます。

condaactivateおよびcondadeactivateコマンドは、conda4.6以降のバージョンでのみ機能することに注意してください。 4.6より前のバージョンのcondaの場合は、代わりに次のコマンドを実行してください:sourceactivateまたはsourcedeactivate
Anaconda環境のセットアップ
マシンにAnacondaをインストールしたばかりですが、データサイエンスにAnacondaを使用する前に、環境をセットアップする必要があります。 環境は、さまざまなバージョンのPythonとパッケージをインストールできるファイルシステム上の個別の場所です。
この設定は、異なるPythonまたはパッケージバージョンを必要とする複数のプロジェクトで作業する必要がある場合に役立ちます。
チュートリアル全体のこの時点から、環境とファイルに任意の名前を付けることができます。
Anaconda環境をセットアップするには:
1.を実行します コンダ作成 以下のコマンドを使用して、Python3(python = 3)を実行するmy_envという名前の新しい環境を作成します。
conda create --name my_env python=3
2.次に、yを入力し、環境の作成を続行するかどうかを選択するように求められたら、Enterキーを押します。
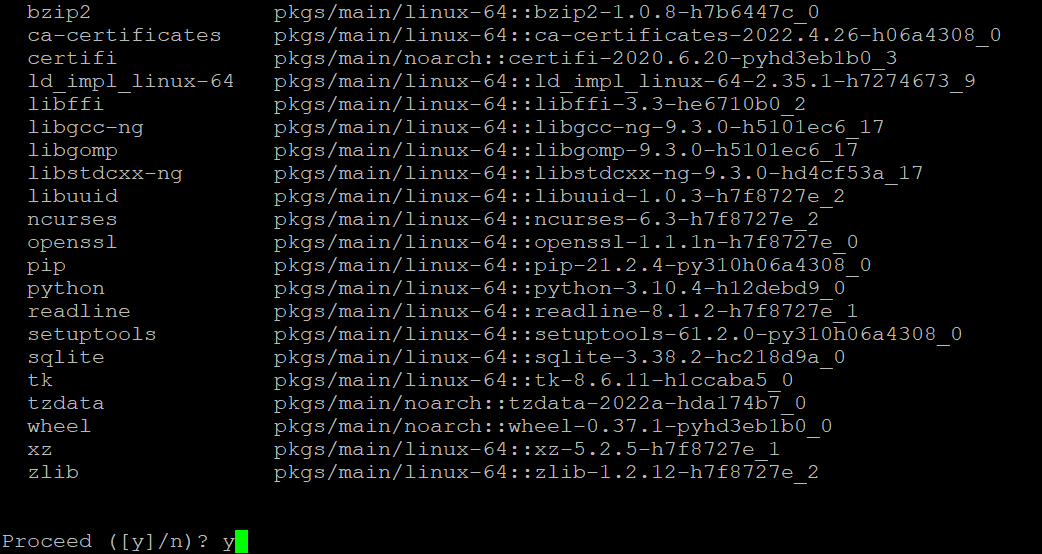
3.環境が作成されたら、以下のconda activateコマンドを実行して、新しい環境(my_env)をアクティブ化します。

4.次に、以下を実行します conda create のデータサイエンスに必要な、以下にリストされているすべてのコアPythonライブラリとツールをインストールするコマンド data_env 環境:
scipy–データ分析タスクを実行するための科学計算用の人気のあるPythonライブラリ。
numpy –多次元配列を操作するためのライブラリ。
pandas–表形式のデータを操作するための強力で直感的な方法を提供するデータ分析用の便利なライブラリ。
matplotlib–データの高度な視覚化を作成するために使用されるプロットライブラリ。
conda create --name data_env python=3 numpy scipy pandas matplotlib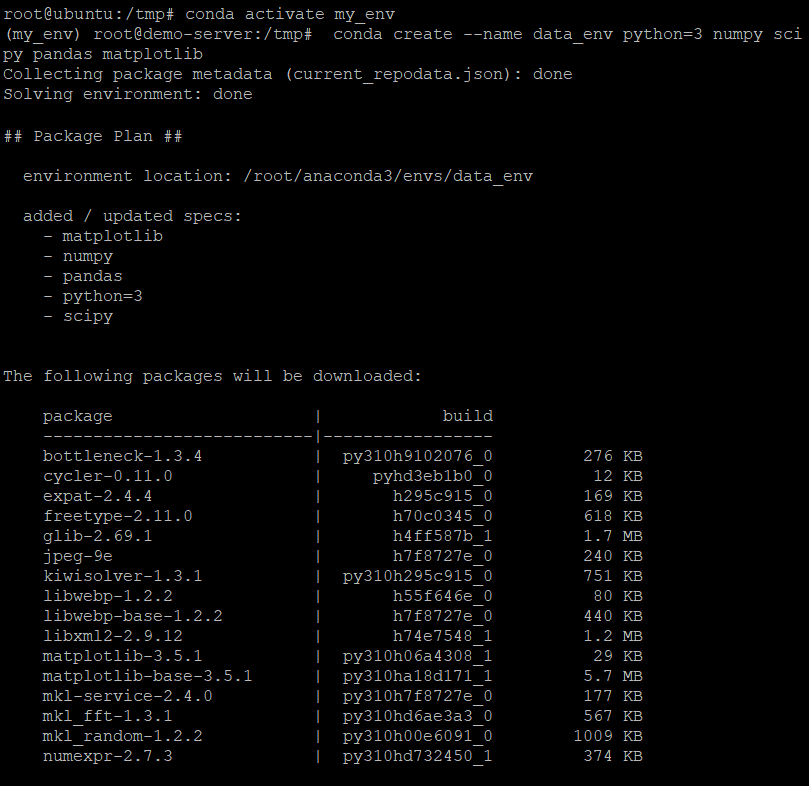
5. yを入力し、Enterキーを押して、data_env環境の作成を続行します。
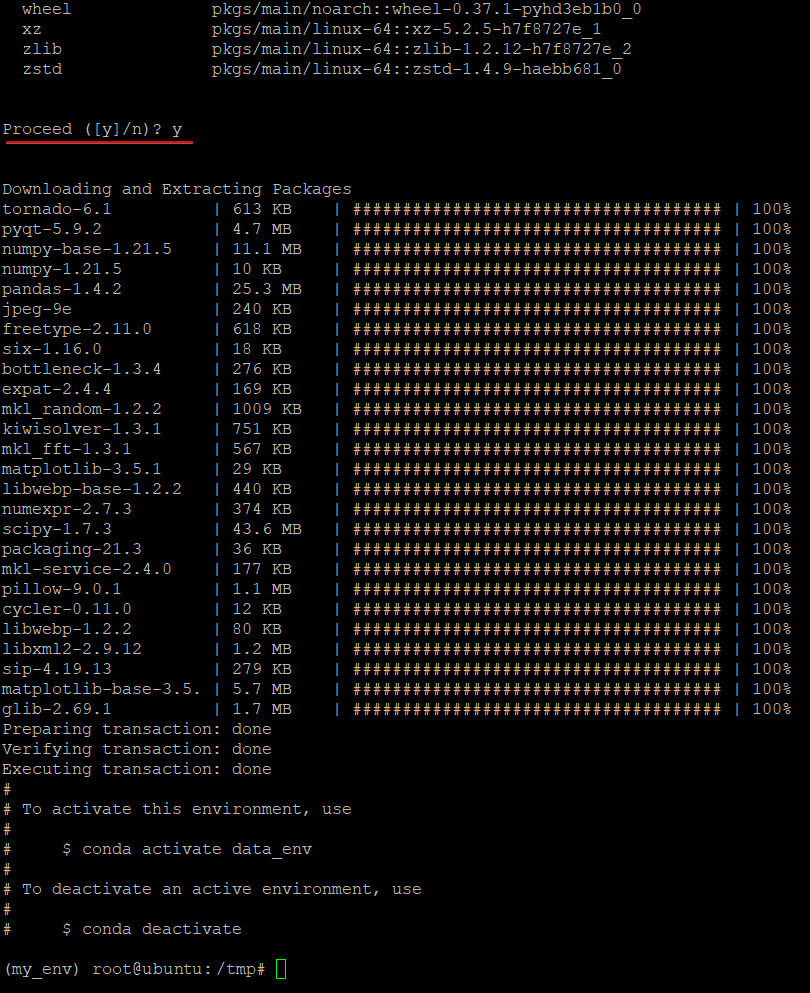
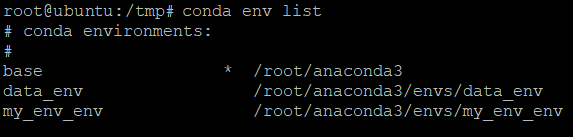
6.最後に、次のconda envコマンドを実行して、使用可能な環境のリストを確認します。
以下に示すように、基本環境を含む、マシン上に作成されたすべての環境が表示されます。
最初のPythonプログラムの実行
これで環境が実行されました。これはすばらしいことです。 しかし、プログラムを作成しない限り、環境は現在あまり機能していません。 このチュートリアルでは、環境を使用して、単純な年齢計算機Pythonプログラムを作成して実行します。
ご使用の環境でPythonプログラムを作成するには:
1.以下のコマンドを実行して、環境(my_env)をアクティブ化します。

2.次に、以下のコマンドを実行してPythonインタープリターを開きます。 PythonインタープリターはREPL(read-evaluate-print loop)環境であり、Pythonコードをインタラクティブに記述して実行できます。

3.次のコードをコピーしてインタプリタに貼り付け、Enterキーを押します。
このコードブロックは、1900年に生まれ、1970年に減少した人の死亡年齢を計算して出力します。
birth_year = 1900
death_year = 1970
age_at_death = death_year - birth_year
print(age_at_death)以下に、端末に印刷された出力70を示します。これは、その人が亡くなったときに70歳であったことを示しています。
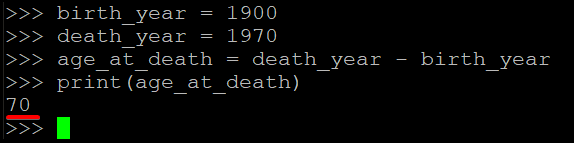
4.次に、以下のexit()コマンドを実行して、Pythonインタープリターを終了します。

5.最後に、以下のコマンドを実行して、my_env環境のセッションを閉じて終了します。

最初のデータサイエンスプロジェクトの構築
これまで、ご使用の環境を使用して単純なPythonプログラムを実行する方法を見てきました。 しかし今回は、最初のプロジェクトを作成して、データサイエンスゲームを強化します。 データサイエンスプロジェクトには通常、特定のビジネスニーズや問題に対処するためのデータの収集、調査、分析、および視覚化が含まれます。
最初のデータサイエンスプロジェクトを構築するには、matplotlibライブラリを使用して光(X、Y)散布図でデータをプロットします。
1.以下のcondaactivateコマンドを実行して、data_envという環境をアクティブ化します。

2.次に、というPythonファイルを作成します scatter.py お好みのテキストエディタを使用します。
3.以下のコードをに入力します scatter.py ファイルを作成し、変更を保存してエディタを閉じます。 このコードブロックは、それぞれ12個の要素を持つ2つの配列を作成し、データポイントをプロットして表示します。
# Imports matplotlib.pyplot to visualize the plot
import matplotlib.pyplot as plt
# Contains an array of numbers (cars ages) to x.
x = [5,7,8,7,2,17,2,9,4,11,12,9,6]
# Contains an array of nunbers (cars speeds) to y.
y = [99,86,87,88,111,86,103,87,94,78,77,85,86]
# Plot the data points
plt.scatter(x, y)
# Show the plotted data points
plt.show()4.最後に、以下のコマンドを実行して、画面にプロットを表示するPythonファイル(scatter.py)を実行します。
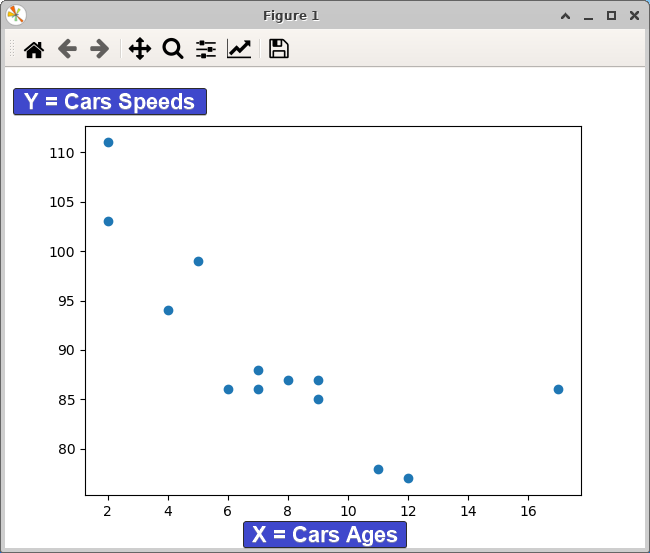
以下に示すように、グラフにプロットされたデータポイントが表示されます。 車の年齢と速度の関係は明確であり、車のフリートのパフォーマンスを維持または改善する方法についての決定を通知するのに役立ちます。
明らかな関係は、車の年齢が上がるにつれて、車が移動できる速度が低下することです。
また、年齢と速度の間にわずかな正の相関関係があることに気付くかもしれません。車の年齢が上がると、速度もわずかに上がる傾向があります。 この関係は、パフォーマンスと効率のために車両を最適化したい自動車メーカーにとって有用です。
あります! これで、LinuxにAnacondaが正常にインストールされ、最初のデータサイエンスプロジェクトが作成されました。
環境の削除
環境はストレージを消費します。特に、目的を果たさなくなったストレージを保持している場合はなおさらです。 それらを削除してみませんか? The conda env remove 削除する環境の名前を知っている限り、トリックを実行します。
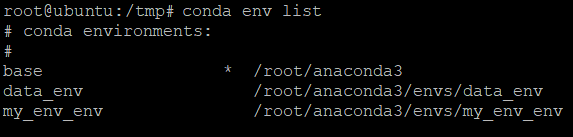
以下のコマンドを実行して、すべての環境を一覧表示します。
削除する予定の環境の名前を書き留めます。
次に、次のコマンドを実行して remove (という名前の環境-n)。 data_env。 交換 data_env 削除するターゲット環境の名前を使用します。
conda env remove -n data_env

または、パスを指定して以下のコマンドを実行することもできます(-p)環境が置かれている場所(/root/anaconda3/envs/data_env)。
conda env remove -p /root/anaconda3/envs/data_env

結論
このチュートリアルでは、Ubuntu LinuxにAnacondaをインストールし、データサイエンス用のPython3環境を作成する方法を学びました。 最初のプログラムを作成し、matplotlibを使用してデータをプロットしました。
この時点で、これらのスキルを備えたデータサイエンティストとしての旅を始める準備が整いました。
データサイエンスの旅を始めてみませんか アナコンダナビゲーター? 独自のプロジェクトのデータの調査、分析、および視覚化を開始してください。
The post LinuxにAnacondaをインストールしてデータサイエンスを成功させる方法が勝ちです! appeared first on Gamingsym Japan.