
サンプル
サンプルのDataFrameを作成することから始めましょう。
#パンダをインポート
輸入 パンダ なので pd
df = pd。DataFrame(({{
‘給料’: [120000, 100000, 90000, 110000, 120000, 100000, 56000]、
‘デパートメント’: [‘game developer’, ‘database developer’, ‘front-end developer’, ‘full-stack developer’, ‘database developer’, ‘security researcher’, ‘cloud-engineer’]、
「評価」: [4.3, 4.4, 4.3, 3.3, 4.3, 5.0, 4.4]}、
索引=[‘Alice’, ‘Michael’, ‘Joshua’, ‘Patricia’, ‘Peter’, ‘Jeff’, ‘Ruth’])。
印刷((df)。
上記のように、サンプルデータを使用してDataFrameを作成する必要があります。

パンダのdtype属性
Pandasで列のデータ型を取得する最も簡単な方法は、dtypes属性を使用することです。
構文は次のとおりです。
この属性は、各列とそれに対応するデータ型を返します。
例は次のとおりです。
上記は、示されているように列とそのデータ型を返す必要があります。
給与int64
デパートメント 物体
定格float64
特定の列のデータ型を取得する場合は、次のように列名をインデックスとして渡すことができます。
これにより、次のように給与列のデータ型が返されます。
パンダの列情報
パンダはinfo()メソッドも提供します。 これにより、PandasDataFrame内の列に関する詳細情報を取得できます。
構文は次のとおりです。
DataFrame。情報((冗長=なし、 buf=なし、 max_cols=なし、 メモリ使用量=なし、 show_counts=なし、 null_counts=なし)。
これにより、列の名前、データ型、null以外の要素の数などを取得できます。
例は次のとおりです。
これは戻るはずです:
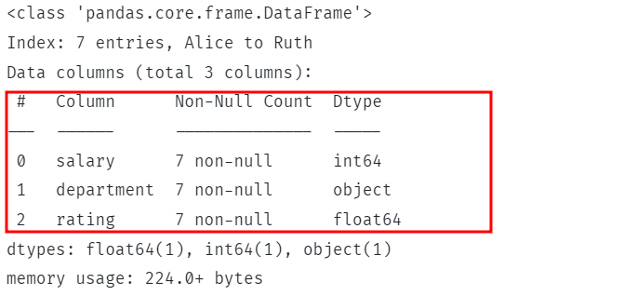
上記は、データ型を含む、DataFrameの列に関する詳細情報を示しています。
結論
このチュートリアルでは、PandasDataFrameの列のデータ型をフェッチするために使用できる2つの方法について説明します。
読んでくれてありがとう!!
The post パンダチェックカラムタイプ appeared first on Gamingsym Japan.