
AI画像の競争は個人的になりつつあります。
Googleは今週、OpenAIの自慢のDALLE-2テキストから画像へのジェネレーターへの新しい挑戦者を発表しました—そしてライバルの努力を撃ちました。
どちらのモデルも、テキストプロンプトを画像に変換します。 しかし、Googleの研究者は、彼らのシステムが「前例のないフォトリアリズムと深い言語理解。」

ヒューマノイドのご挨拶
今すぐ購読して、お気に入りのAIストーリーの毎週の要約をご覧ください
![:ImagenとDALL-E2の定性的な比較の例 [54] ConflictingカテゴリのDrawBenchプロンプトで。 DALL-E 2とImagenの両方が、このカテゴリの適切に位置合わせされた画像を生成するのに苦労していることがわかります。 ただし、Imagenは、「ラテアートを作るパンダ」などの適切に配置されたサンプルを生成することがよくあります。](https://cdn0.tnwcdn.com/wp-content/blogs.dir/1/files/2022/05/Screenshot-2022-05-25-at-10.58.07.png)
しつこい名前のImagenシステムは、事前にトレーニングされた大規模な言語モデルをテキストエンコーダーとして使用します。 のカスケード 拡散モデル 次に、ユーザーの言葉を写真に変えます。
テストでは、GoogleチームはImagenがDALL-E2を「大幅に上回った」と述べました。
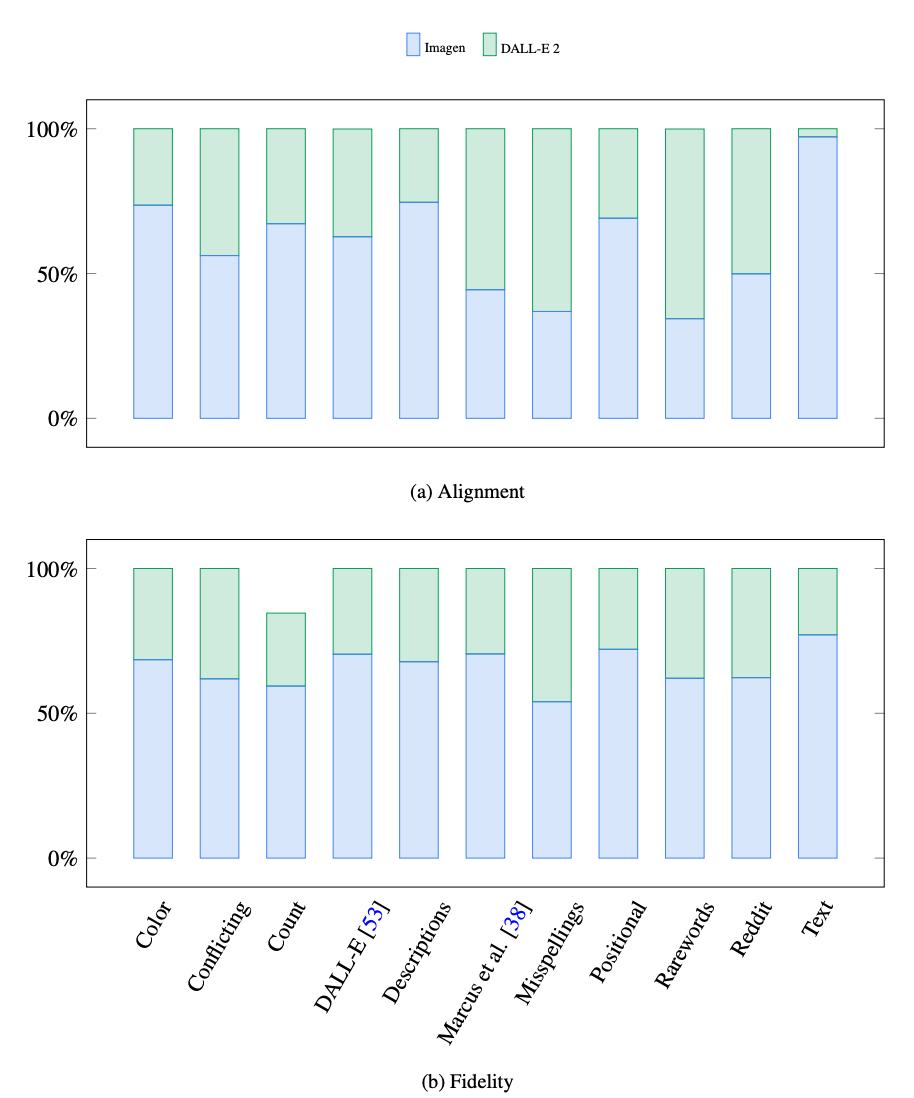
Imagenの開発者は、自分たちの作成の優位性を測定する新しい方法を発明しました。
DrawBenchと呼ばれるこのベンチマークは、さまざまなテキストから画像へのジェネレーターの出力に関する人間の判断を比較します。
当然のことながら、Googleの指標はGoogleのシステムに強いスコアを与えました。
「DrawBenchを使用すると、人間による広範な評価により、Imagenが他の最近の方法よりも大幅に優れていることがわかります」と研究者は述べています。 彼らの研究論文。
![ImagenとDALL-E2の定性的な比較の例 [54] ColorsカテゴリのDrawBenchプロンプトで。 DALL-E 2は、特に複数のオブジェクトを含むプロンプトの場合、オブジェクトに色を正しく割り当てるのに一般的に苦労していることがわかります。](https://cdn0.tnwcdn.com/wp-content/blogs.dir/1/files/2022/05/Screenshot-2022-05-25-at-10.56.15.png)
画像と指標は確かに印象的ですが、Googleは結果を精査する機会を提供していません。
あなたはでいくつかのインタラクティブなデモを試すことができます ImagenのWebサイト、ただし、これらは、制約された文を形成するために少数のフレーズを使用することのみを可能にします。
モデルとコードが公開されるまで、皮肉屋はグーグルが結果を厳選しているのではないかと疑うでしょう。
![ImagenとDALL-E2の定性的な比較の例 [54] テキストカテゴリからのDrawBenchプロンプト。 Imagenは、引用符で囲まれたテキストを含むプロンプトでDALL-E2よりも大幅に優れています。](https://cdn0.tnwcdn.com/wp-content/blogs.dir/1/files/2022/05/Screenshot-2022-05-25-at-10.59.38.png)
モデルをプライベートに保つためのGoogleの説明は、OpenAIによって与えられたものと同じです。システムは危険すぎてリリースできません。
研究者たちは、生成的方法が誤った情報を広め、嫌がらせをかき立て、疎外を悪化させる可能性があると警告しています。
「私たちの予備評価では、Imagenがいくつかの社会的バイアスとステレオタイプをエンコードしていることも示唆しています。これには、肌の色が薄い人の画像を生成する全体的なバイアスや、さまざまな職業を描いた画像が西洋の性別のステレオタイプと一致する傾向が含まれます」と研究者は述べています。
![ImagenとDALL-E2の定性的な比較の例 [54] RedditカテゴリのDrawBenchプロンプトで。](https://cdn0.tnwcdn.com/wp-content/blogs.dir/1/files/2022/05/Screenshot-2022-05-25-at-10.54.57.png)
チームは、Imagenは「現時点では一般公開には適していません」と結論付けていますが、将来のリリースの希望を提供しています。
慎重に更新をお待ちしております。 毎日記事の画像を作成する人として、より良い結果を提供するために競合するAIラボの見通しは魅力的です。
一方で、私はロボットの大君主がアーティストをアルゴリズムに置き換えてほしくありません。
The post Googleは派手なテキストから画像へのジェネレータでOpenAIを採用しています appeared first on Gamingsym Japan.