
例えば、気に入った商品の評価を知るためにAmazonの口コミを探したら、大量のコメントが書かれていたりとか、調べものをググって辿り着いたWebサイトに大量の文書が書かれていた場合、それらに全て目を通すのって大変ですよね。
有難いことに、Pythonを使って大量の文書から要点を要約する手段として、sumy というライブラリが存在します。
そこで、この記事では sumy のインストールと使い方について解説したいと思います。
しかも、誰でも簡単に sumy を使った文書要約が出来よう、Python用のクラスを作ったので、それをベースに解説します。
とりあえず試してみたい方は、掲載しているソースコードをコピペして直ぐにでもお使いいただけます。
sumyの概要
sumy は文章の自動要約が可能なPythonライブラリで、日本語を含む複数な言語に対応しています。
また、8種類のアルゴリズムが用意されており、簡単に使い分け出来るようになっています。
アルゴリズムの詳細については、こちら(GitHub)のページにも記載されていますが、AIベンダーのHakkyに図入りで解説されていますので、興味のある方はご覧ください。
ここでは、簡単にアルゴリズムについて触れておきます。
| 名前 | 概要 |
|---|---|
| Luhn | 最も重要な文は最も重要な単語を含む文であるという仮定に基づくアルゴリズム 「重要な単語=登場頻度が高い」という前提であるため、ストップワード(評価に関係ない単語)を与えないと精度が悪くなる。 |
| Edmundson | Luhnの拡張版で、要約精度を上げるために次の3種類の情報を指定する必要がある。 bouns_words:重要、素晴らしい、栄光、最適、有名、等のポジティブなワードリスト tigma_words:不可能、出来ない、駄目、等のネガティブなワードリスト null_words :且つ、又は、ここ、何故、等の評価に無関係なワードリスト |
| LSA | Latent Semantic Analysis の略 代数的なアプローチ方法を用いており、テキスト内の同義語と明示的に記述されていないトピックの識別が可能。 プレーンテキストやHTMLドキュメントに適している。 |
| TextRank | Google検索の基礎であるPageRankという手法を応用したもの。 文/単語をノード、文/単語の類似度をエッジとしてグラフ構造を作り、共通の単語が含まれる割合で類似度を判定する。 そして、類似度が高い文書が多いほど重要だと考えて要約する。 |
| LexRank | TextRankと同じだが、TF-IDFを用いて類似度を算出する点が異なる |
| SumBasic | 出現頻度が高い単語が含まれる文書を優先して要約する。他のアルゴリズムとの比較用として用いられる。 |
| KL-Sum | 2つの文書における単語の確率分布を計算し、確率分布の類似度が高いものを重要と判断する。 Kullback-Leibler divergence(KLダイバージェンス、KL情報量)という手法を使っている。 |
| Reduction | 文書からグラフ(頂点と頂点動詞の関係を表した構造)を作成し、他の文に対するエッジの重みの合計によって重要度を判断する。 |
インストール方法
まず、以下の通り pip コマンドで必要なライブラリをインストールします。
pip install sumy pip install tinysegmenter pip install spacy pip install -U ginza ja-ginza
sumyの使い方
以下の通り、必要なモジュールをimport します。
#必ずimportが必要 from sumy.parsers.plaintext import PlaintextParser from sumy.nlp.tokenizers import Tokenizer #以下はアルゴリズムに応じて import する from sumy.summarizers.lex_rank import LexRankSummarizer from sumy.summarizers.lsa import LsaSummarizer from sumy.summarizers.reduction import ReductionSummarizer from sumy.summarizers.luhn import LuhnSummarizer from sumy.summarizers.sum_basic import SumBasicSummarizer from sumy.summarizers.kl import KLSummarizer from sumy.summarizers.text_rank import TextRankSummarizer from sumy.summarizers.edmundson import EdmundsonSummarizer
下記は、もっとも簡単なサンプルです。
from sumy.parsers.plaintext import PlaintextParser
from sumy.nlp.tokenizers import Tokenizer
from sumy.summarizers.lex_rank import LexRankSummarizer
#要約対象のテキスト
text = "スタートレックには長い歴史がある。現在も人気が衰えず、次々と新作が登場している。"
#要約対象のテキストを指定
parser = PlaintextParser.from_string(text, Tokenizer('japanese'))
#アルゴリズムのインスタンス生成
summarizer = LexRankSummarizer()
#要約の実行 sentences_count で何行に要約したいかを指定する
res = summarizer(document=parser.document, sentences_count=5)
summarizer の結果は 要約した行数がリストで返されるのですが、1つ1つの要素は文字列ではなくsumy.models.dom._sentence.Sentence というクラスになっています。

このクラスからは __str__() メソッドで文書を取り出すことが出来ます。
従って、summarizer から受け取った結果(res 変数) を 次の様にfor ループで回すことで、要約行を全て取り出す事が出来ます。
#要約結果の取り出し
for sentence in res:
print(sentence.__str__())
文書要約クラスについて
では、さっそく文書要約クラスの概要、リファレンス、ソースコードの順に紹介していきたいと思います。
クラスの概要
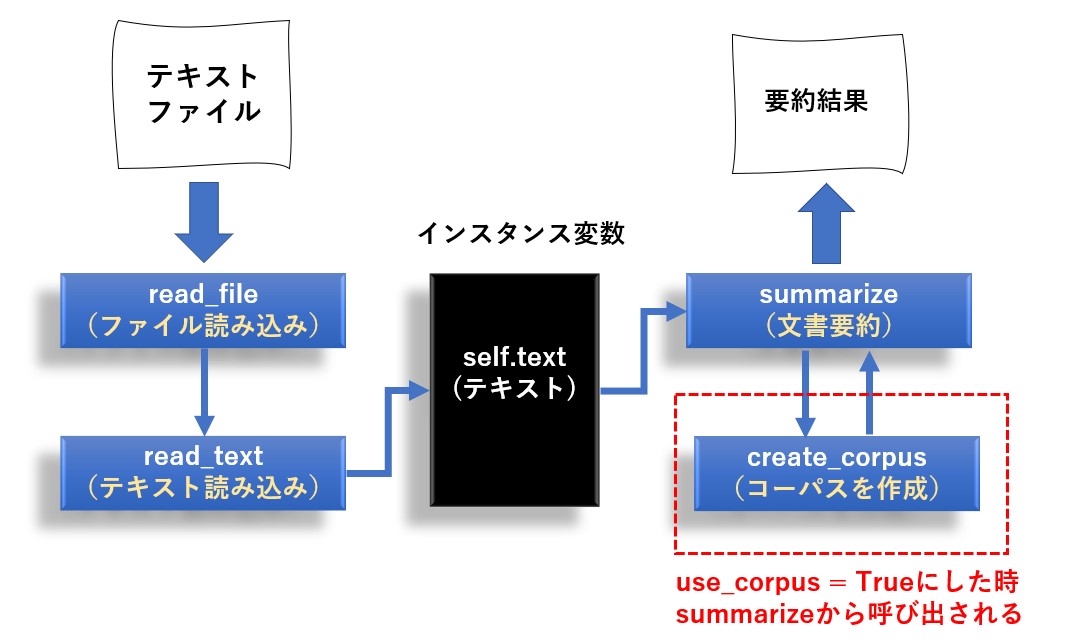
read_file 又は read_text メソッドで要約したい文書を読み込み、summarize メソッドで文書を要約します。
create_corpus は読み込んだテキストからコーパス(言葉のデータベース)を作るメソッドなのですが、use_corpus プロパティを True にした時だけ、summarize メソッド内で呼び出されます。
リファレンス
メソッドは次の4つがあります。
| 機能 | メソッド仕様 | 戻り値 | 補足 |
|---|---|---|---|
| ファイル読み込み | read_file(filename, encoding=’utf-8′) |
なし | |
| テキスト読み込み | read_text(text) | なし | |
| 要約の実行 | summarize(algo) | 要約結果(文字列) のリスト [‘aaa’,’bbb’・・・] |
algo には次の文字列の指定が可能 ‘lex’ :LexRank ‘txt’ :TextRank ‘red’ :Reduction ‘luh’ :Luhn ‘sum’ :SumBasic ‘kls’ :KLS ‘lsa’ :LSA ‘edm’ :Edmundson |
| コーパスの作成 | create_corpus(text) | (origilan,corpus) | original:元の文書 corpus:生成されたコーパス |
プロパティは次の4つがあります。
| 意味 | メソッド仕様 | 値 | 補足 |
|---|---|---|---|
| コーパスの利用有無 | use_corpus | True/False | |
| 要約したい行数 | sentences_count | 整数 | |
| 要約の評価上対象外として 扱いたいキーワード |
stop_words | [‘aaa’,’bbb’,・・・] | |
| 要約の評価上ポジティブとして 扱いたいキーワード |
bonus_words | [‘aaa’,’bbb’,・・・] | Edmundsonでのみ指定可能 |
| 要約の評価上ネガティブとして 扱いたいキーワード |
stigma_words | [‘aaa’,’bbb’,・・・] | Edmundsonでのみ指定可能 |
| 要約の評価上 無視したいキーワード |
null_words | [‘aaa’,’bbb’,・・・] | Edmundsonでのみ指定可能 |
use_corpus を True にすると、元の文書の分かち書きに原型(例:起きて⇒起きた)が追加されたものでコーパスが作成されます。
| use_corpus | 文書 | |
|---|---|---|
| False | 設定では、2026年から2053年にかけて発生した第三次世界大戦により、6億人の犠牲者と文明の崩壊が起きている。 | 元の文書そのまま |
| True | 設定 で は 、 2026 年 から 2053 年 に かける て 発生 する た 第 三 次 世界 大戦 に よる 、 6億 人 の 犠牲者 と 文明 の 崩壊 が 起きる て いる 。 | 分かち書き+原型の追加 |
ただ、文字によって正しくコーパス化できないケースが発生し、指定した要約の行数より少ない結果しか得られないことがあるので、状況によって使い分けが必要です。
使い方
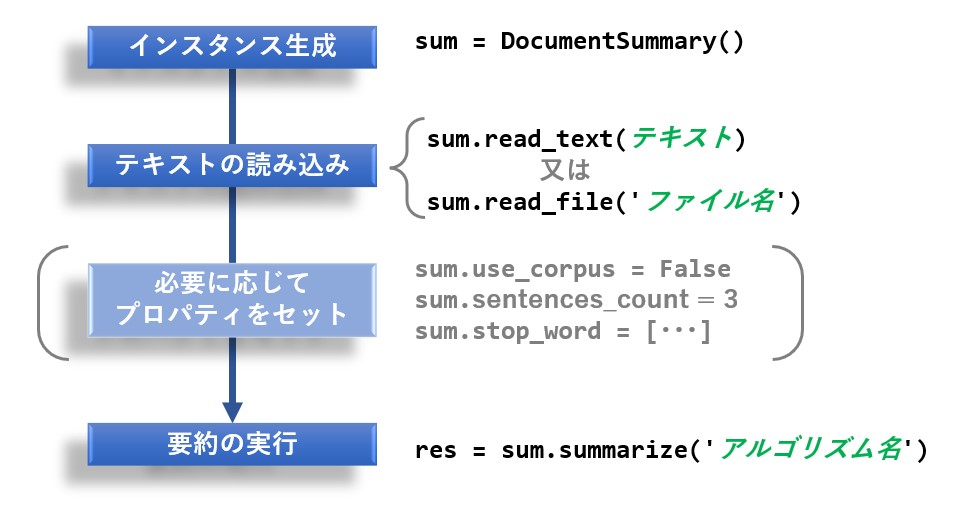
クラスの使い方は次の通りです。
尚、アルゴリズムに ‘luh’ を指定した場合は stop_words を、 ‘edm’ を選択した場合はbonus_words、stigma_words、null_wordsに適切なキーワードを指定しないと、良い結果が得られないようです。
下記は一通りのアルゴリズムで要約させる場合のサンプルコードになります。
sum = DocumentSummary()
sum.use_corpus= False
sum.sentences_count = 4
sum.read_file('p:/startreck.txt')
print(sum.text)
print("★★★ LexRankによる要約 =================================")
print(sum.summarize('lex'))
print("★★★ TextRankによる要約 =================================")
print(sum.summarize('txt'))
print("★★★ Reductionによる要約 =================================")
print(sum.summarize('red'))
print("★★★ Luhnよる要約 =================================")
print(sum.summarize('luh'))
print("★★★ SumBasicによる要約 =================================")
print(sum.summarize('sum'))
print("★★★ KLSによる要約 =================================")
print(sum.summarize('kls'))
print("★★★ LSA(Latent Semantic Analysis)による要約 =================================")
print(sum.summarize('lsa'))
print("★★★ Edmundsonによる要約 =================================")
print(sum.summarize('edm'))
サンプルソースは、下記の文書を startreck.txt というファイル名で保存したものを使っています。
検証で使ったPCはWindows10マシンで、Pドライブ直下に保存していますので、皆さんの環境に合わせて変更をお願いします。
スタートレックは、22世紀から24世紀の話である。設定では、2026年から2053年にかけて発生した第三次世界大戦により、6億人の犠牲者と文明の崩壊が起きている。2063年にゼフラム・コクレーンがワープエンジンを開発、試験飛行中にバルカン時に発見され、ファーストコンタクトを果たした。 2151年には初代エンタープライズ号「NX-01」が竣工し、クリンゴンとのファーストコンタクトを果たしている。2153年にロミュラン人との戦争が勃発、2161年に地球連合、バルカン、アンドリアが中心になり惑星連邦が設立された。 地球人は銀河系内の約4分の1の領域に進出し、様々な異星人との交流を行っている。 既に貧困や戦争などは根絶されており、見た目や無知から来る偏見、差別も存在しない、理想的な世界となっている。 レプリケーターの登場により貨幣経済は無くなり、人間は富や欲望ではなく人間性の向上を目指して働いている。 しかし、個人財産は存在しており、ワイナリーや宇宙船を所有する一部の恵まれた人々が存在する。 惑星連邦の本部はパリにあり、宇宙艦隊の本部はサンフランシスコに存在する。 惑星連邦内では軍事力による紛争が根絶されたが、クリンゴン帝国やロミュラン帝国、カーデシア連合などの侵略的な星間国家とは必ずしも良好な関係を築けていない。 『スタートレック:エンタープライズ』では惑星連邦設立以前の時代を、『スタートレック:ディスカバリー』では、地球連合やバルカン星などが脱退、惑星連邦が瓦解した32世紀の世界が描かれている。 長く続く作品では、これまでの作品を「なかったこと」にし、設定を一新することがしばしばあるが、スタートレックのシリーズではほぼすべての作品が同じ宇宙を共有している。 一方、作品の根幹としてマルチバースの概念が取り入れられ、物語の主軸として描かれている宇宙とは異なる平行宇宙(パラレルワールド)が登場することもある。 劇場版第11作から劇場版第13作まではリブート作品ではあるが、タイムトラベルの影響で歴史が変わったという設定で、シリーズとしての連続性は保たれている。 タイムトラベルを扱った作品はスタートレックの中でしばしば登場し、異なる歴史を持つパラレルワールドがいくつも存在している。
以下はアルゴリズムごとの要約結果です。
| アルゴリズム | 要約結果(4行) |
|---|---|
| LexRank | 2153年にロミュラン人との戦争が勃発、2161年に地球連合、バルカン、アンドリアが中心になり惑星連邦が設立された。 『スタートレック:エンタープライズ』では惑星連邦設立以前の時代を、『スタートレック:ディスカバリー』では、地球連合やバルカン星などが脱退、惑星連邦が瓦解した32世紀の世界が描かれている。 長く続く作品では、これまでの作品を「なかったこと」にし、設定を一新することがしばしばあるが、スタートレックのシリーズではほぼすべての作品が同じ宇宙を共有している。 タイムトラベルを扱った作品はスタートレックの中でしばしば登場し、異なる歴史を持つパラレルワールドがいくつも存在している。 |
| TextRank | 『スタートレック:エンタープライズ』では惑星連邦設立以前の時代を、『スタートレック:ディスカバリー』では、地球連合やバルカン星などが脱退、惑星連邦が瓦解した32世紀の世界が描かれている。 長く続く作品では、これまでの作品を「なかったこと」にし、設定を一新することがしばしばあるが、スタートレックのシリーズではほぼすべての作品が同じ宇宙を共有している。 一方、作品の根幹としてマルチバースの概念が取り入れられ、物語の主軸として描かれている宇宙とは異なる平行宇宙(パラレルワールド)が登場することもある。 劇場版第11作から劇場版第13作まではリブート作品ではあるが、タイムトラベルの影響で歴史が変わったという設定で、シリーズとしての連続性は保たれている。 |
| Reduction | 『スタートレック:エンタープライズ』では惑星連邦設立以前の時代を、『スタートレック:ディスカバリー』では、地球連合やバルカン星などが脱退、惑星連邦が瓦解した32世紀の世界が描かれている。 長く続く作品では、これまでの作品を「なかったこと」にし、設定を一新することがしばしばあるが、スタートレックのシリーズではほぼすべての作品が同じ宇宙を共有している。 一方、作品の根幹としてマルチバースの概念が取り入れられ、物語の主軸として描かれている宇宙とは異なる平行宇宙(パラレルワールド)が登場することもある。 劇場版第11作から劇場版第13作まではリブート作品ではあるが、タイムトラベルの影響で歴史が変わったという設定で、シリーズとしての連続性は保たれている。 |
| Luhn | 2153年にロミュラン人との戦争が勃発、2161年に地球連合、バルカン、アンドリアが中心になり惑星連邦が設立された。 『スタートレック:エンタープライズ』では惑星連邦設立以前の時代を、『スタートレック:ディスカバリー』では、地球連合やバルカン星などが脱退、惑星連邦が瓦解した32世紀の世界が描かれている。 長く続く作品では、これまでの作品を「なかったこと」にし、設定を一新することがしばしばあるが、スタートレックのシリーズではほぼすべての作品が同じ宇宙を共有している。 劇場版第11作から劇場版第13作まではリブート作品ではあるが、タイムトラベルの影響で歴史が変わったという設定で、シリーズとしての連続性は保たれている。 |
| SumBasic | 2153年にロミュラン人との戦争が勃発、2161年に地球連合、バルカン、アンドリアが中心になり惑星連邦が設立された。 既に貧困や戦争などは根絶されており、見た目や無知から来る偏見、差別も存在しない、理想的な世界となっている。 レプリケーターの登場により貨幣経済は無くなり、人間は富や欲望ではなく人間性の向上を目指して働いている。 長く続く作品では、これまでの作品を「なかったこと」にし、設定を一新することがしばしばあるが、スタートレックのシリーズではほぼすべての作品が同じ宇宙を共有している。 |
| KLS | スタートレックは、22世紀から24世紀の話である。 2153年にロミュラン人との戦争が勃発、2161年に地球連合、バルカン、アンドリアが中心になり惑星連邦が設立された。 惑星連邦の本部はパリにあり、宇宙艦隊の本部はサンフランシスコに存在する。 劇場版第11作から劇場版第13作まではリブート作品ではあるが、タイムトラベルの影響で歴史が変わったという設定で、シリーズとしての連続性は保たれている。 |
| LSA | 設定では、2026年から2053年にかけて発生した第三次世界大戦により、6億人の犠牲者と文明の崩壊が起きている。 既に貧困や戦争などは根絶されており、見た目や無知から来る偏見、差別も存在しない、理想的な世界となっている。 惑星連邦内では軍事力による紛争が根絶されたが、クリンゴン帝国やロミュラン帝国、カーデシア連合などの侵略的な星間国家とは必ずしも良好な関係を築けていない。 長く続く作品では、これまでの作品を「なかったこと」にし、設定を一新することがしばしばあるが、スタートレックのシリーズではほぼすべての作品が同じ宇宙を共有している。 |
| Edmundson | 設定では、2026年から2053年にかけて発生した第三次世界大戦により、6億人の犠牲者と文明の崩壊が起きている。 地球人は銀河系内の約4分の1の領域に進出し、様々な異星人との交流を行っている。 『スタートレック:エンタープライズ』では惑星連邦設立以前の時代を、『スタートレック:ディスカバリー』では、地球連合やバルカン星などが脱退、惑星連邦が瓦解した32世紀の世界が描かれている。 長く続く作品では、これまでの作品を「なかったこと」にし、設定を一新することがしばしばあるが、スタートレックのシリーズではほぼすべての作品が同じ宇宙を共有している。 |
ソースコード
クラスのソースコードは次の通りです。
from sumy.parsers.plaintext import PlaintextParser
from sumy.nlp.tokenizers import Tokenizer
from sumy.summarizers.lex_rank import LexRankSummarizer
from sumy.summarizers.lsa import LsaSummarizer
from sumy.summarizers.reduction import ReductionSummarizer
from sumy.summarizers.luhn import LuhnSummarizer
from sumy.summarizers.sum_basic import SumBasicSummarizer
from sumy.summarizers.kl import KLSummarizer
from sumy.summarizers.text_rank import TextRankSummarizer
from sumy.summarizers.edmundson import EdmundsonSummarizer
import spacy
import codecs
class DocumentSummary:
def __init__(self):
'''
コンストラクタ
'''
#アルゴリズムの一覧
self.algorithm = {
'lex':LexRankSummarizer(),
'txt':TextRankSummarizer(),
'red':ReductionSummarizer(),
'luh':LuhnSummarizer(),
'sum':SumBasicSummarizer(),
'kls':KLSummarizer(),
'lsa':LsaSummarizer(),
'edm':EdmundsonSummarizer()
}
#コーパスの利用有無
self.use_corpus = True
#要約の文書数
self.sentences_count = 10
#ストップワード
self.stop_words = ['']
#EdmundsonSummarizer用のポジティブキーワード
self.bonus_words = ['']
#EdmundsonSummarizer用のネガティブキーワード
self.stigma_words = ['']
#EdmundsonSummarizer用の無視キーワード
self.null_words = ['']
#要約対象のテキスト
self.text = None
#作成したコーパス
self.coupus = None
#コーパスの元文書
self.originals = None
#要約に適した加工が施されたテキスト情報
self.parser = None
def create_corpus(self,text):
'''
コーパスを作成する
Parameters:
--------
text : str コーパスを生成したいテキスト
'''
nlp = spacy.load('ja_ginza')
corpus = []
originals = []
doc = nlp(text)
for s in doc.sents:
originals.append(s)
tokens = []
for t in s:
tokens.append(t.lemma_)
corpus.append(' '.join(tokens))
return corpus,originals
def read_file(self,filename,encoding='utf-8'):
'''
要約したいファイルを読み込む
Parameters:
--------
filename : str 要約したい文書が書かれたファイル名
'''
with codecs.open(filename,'r',encoding,'ignore') as f:
self.read_text(f.read())
def read_text(self,text):
'''
要約したいテキストを読み込む
Parameters:
--------
text : str 要約したいテキスト
'''
self.text = text
if self.use_corpus:
#コーパスの作成
self.coupus,self.originals = self.create_corpus(self.text.replace('\r','').replace('\n','').replace('『','「').replace('』','」'))
#連結したcorpusをトークナイズ
self.parser = PlaintextParser.from_string(''.join(self.coupus), Tokenizer('japanese'))
else:
#テキストをそのままトークナイズ
self.parser = PlaintextParser.from_string(self.text, Tokenizer('japanese'))
def summarize(self,algo):
'''
文書を要約する
Parameters:
--------
algo : str アルゴリズム ('lex''red''luh','sum','kls'、など)
stopwords:[str] 文書の終わりを識別する為の文字列をリストで指定
'''
#アルゴリズムの取得
summarizer = self.algorithm[algo]
if algo == 'edm':
summarizer.bonus_words = ['']
summarizer.stigma_words = ['']
summarizer.null_words = ['']
# スペースをストップワードを設定
summarizer.stop_words = self.stop_words
# 文書の要約
summary = summarizer(document=self.parser.document, sentences_count=self.sentences_count)
#要約した結果をリストに格納
res = []
for sentence in summary:
if self.use_corpus:
#特定の文字列が
if sentence.__str__() in self.coupus:
res.append(self.originals[self.coupus.index(sentence.__str__())])
else:
res.append(sentence.__str__())
return '\n'.join([str(x) for x in res])
まとめ
今回は文書要約用のライブラリ sumy のインストール方法、使い方、そしてこれを使った自作クラスの説明、ソースコードについて紹介しました。
sumy は8種類のアルゴリズムを使って文書要約が可能ですが、アルゴリズムによって得意不得意があるようなので、実際に使う場合は事前検証が必要です。
そういうことも含めて、簡単に検証できるようにクラス化しておくと何かと便利です。
とりあえずコピペで使えるので、興味のある方は是非お試しください。
また、実際に使う場合は、状況に応じて個別にテキストのクレンジングが必要だと思いますので、必要に応じてカスタマイズしてご利用ください。