
以前、こちらの記事でC#とMeCabを使った形態素解析の方法について紹介しました。
今回は、PythonとMeCabを使って形態素解析をする方法を解説します。
2022年5月時点において、本家のMeCabは32bit 版しかリリースされておらず、64bit版のPythonでは使うことが出来ません。
今回は、Windows10又は11 且つ Python 64bit版 環境で Mecab を動作させ、形態素解析と分かち書きが出来るまでの手順、ユーザー辞書の登録と利用方法について解説致します。
これからPythonでMeCabを利用されようとする方は、是非ご一読ください。
Python64bit版でMecCab 64bit版を使うための手順
手順は次の通りです。
- MeCab 64bit 版を入手
- MeCab 64bit 版をインストール
- mecab-python3をインストール
- 動作確認を行う
尚、MeCabのユーザー辞書を使ったり、コマンドプロンプトから直接MeCabを利用する場合は、MeCabのインストール先のbinフォルダをWindowsの環境変数に登録しておく方が便利です。
普通にインストールした場合は、下記にMeCabの実行ファイルが格納されていますので、これを環境変数に登録しておきましょう。
C:\Program Files\MeCab\bin
MeCab 64bit 版を入手
インストーラーはこちらからダウンロードできます。
2022年5月現在において、mecab-64-0.996.2.exe がダウンロードされます。
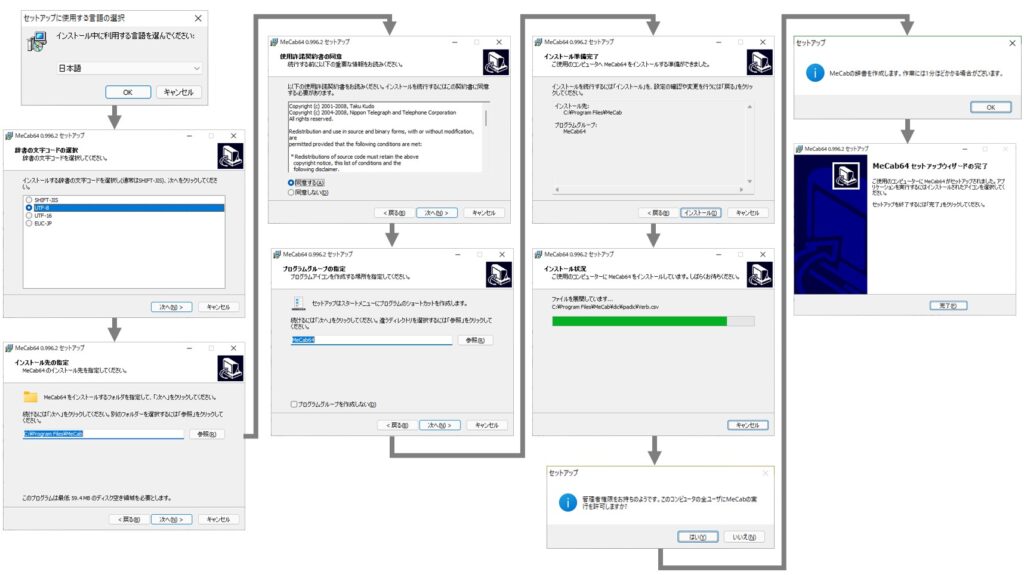
MeCab 64bit 版をインストール
インストーラを、ダブルクリックし、画面のメッセージに従ってインストールします。
この時、辞書の文字コード選択は「UTF-8」を選択しておくことがポイントです。
但し、Womdowsのコマンドプロンプト上で文字化けしますが、ここでは我慢しましょう。
もし、コマンドプロンプト上でしかMeCabを使わないのであれば、初期値(SHIFT-JIS)のままでも問題はありません。
mecab-python3をインストール
コマンドプロンプトを表示して、次のコマンドを実行します。
pip install mecab-python3
動作確認を行う
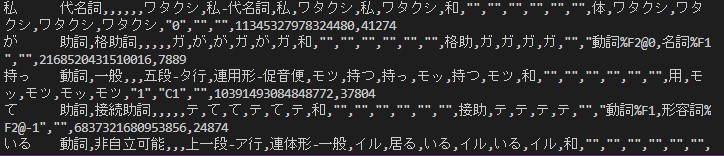
インストールが成功したら、Pythonを起動して次のプログラムを実行して下さい。
tagger = MeCab.Tagger()
result = tagger.parse('私が持っているクレジットカードはJCBとVISAです。')
print(result)
以下の様な結果が表示されればインストールは完了です。
MeCabの使い方
MeCabで形態素解析を行う場合は、parse メソッド、もしくは parseToNode メソッドを使用します。
parseメソッド
parseメソッドは、形態素解析結果を1つの文字列として返します。
tagger = MeCab.Tagger() result = tagger.parse(解析したい文字列)
解析結果は品詞ごとに改行コードで区切られているため、改行コードを使ってリストに分割することが可能です。

ただ、各情報はカンマ区切りなのに対して、品詞と種類の間はタブコード(\t) 区切りになっているため、分解する場合はそれも考慮する必要があります。

具体的には、正規表現モジュールを使って次の様に記述します。
import re
result = [re.split('[,\t]',x) for x in result.splitlines()]
分かち書き
形態素解析結果を自然言語処理で利用する場合、分かち書きしたものを使うことが良くあります。
分かち書きは、それぞれの品詞の間に半角空白を挿入したもので、以下の形式になります。
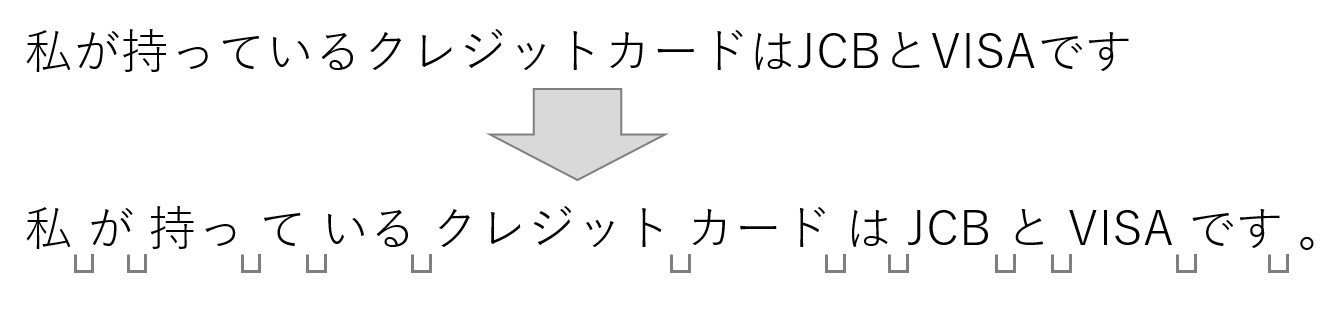
分かち書きの結果が必要な場合は、Tagger メソッドの引数に ‘-Owakati’ を指定するだけです。
tagger = MeCab.Tagger('-Owakati')
result = tagger.parse('私が持っているクレジットカードはJCBとVISAです。')
print(result)
parseToNode メソッド
先ほど、parseメソッドの結果に対して、改行、タブ、カンマを考慮しつつ分解する例を紹介しましたが、実はparseToNodeメソッドとループを組み合わせることで、簡単に分解することが可能です。
parseToNodeは、特定の種類の品詞のみを取り出したい場合に重宝します。
tagger.parseToNode メソッドで返されるオブジェクトのsurface プロパティには品詞が、feture プロパティには品詞の種類以降の情報が格納されています。
feture プロパティをカンマで分割すると、先頭の要素に品詞の種類が格納されているため、これを利用することで、例えば名詞だけを取り出す事が可能です。
tagger = MeCab.Tagger()
words=[]
node = tagger.parseToNode('私が持っているクレジットカードはJCBとVISAです。')
while node:
tkn = node.feature.split(',')
if tkn[0] in ["名詞"]:
words.append(node.surface)
node = node.next
print(words)
ユーザー辞書について
MeCabにユーザー辞書を登録して使うことが可能です。
ユーザー辞書は単にテキストファイルを用意するだけではなく、バイナリ形式に変換して使いますので、ここではその方法と、作成済み辞書の指定方法について説明しておきます。
ユーザー辞書の使用方法
Tagger メソッドの引数にユーザー辞書を指定することで使用できるようになります。
MeCab.Tagger(‘-d システム辞書フォルダ, -u ユーザー辞書のフルパス‘)
例えば、MeCabのシステム辞書フォルダが ‘C:/Program Files/MeCab/dic/ipadic’ 、ユーザー辞書のフルパスが ‘C:/Program Files/MeCab/dic/mydic/userdic.dic’ の場合、次の様に記述します。
MeCab.Tagger('-Owakati -d "C:/Program Files/MeCab/dic/ipadic" -u "C:/Program Files/MeCab/dic/mydic/userdic.dic"')
尚、Program Files の様にフォルダ名やフルパスに半角スペースが含まれている場合は、ダブルクォートで括らないとエラーになるのでご注意ください。
ユーザー辞書の作成方法
ユーザー辞書を作るには、次の手順が必要です。
- CSV形式の辞書ファイルを作成する
- mecab-dict-index.exe コマンドを使って辞書をバイナリ形式に変換する
ユーザー辞書は以下の様なフォーマットである必要があります。
詳細はこちらの公式ページにも記載されているので、併せてご参照下さい。
仕舞い,1285,1285,5543,名詞,一般,*,*,*,*,仕舞い,シマイ,シマイ 綺,1285,1285,5622,名詞,一般,*,*,*,*,綺,アヤギヌ,アヤギヌ 洋裁,1285,1285,5618,名詞,一般,*,*,*,*,洋裁,ヨウサイ,ヨーサイ 組打ち,1285,1285,5622,名詞,一般,*,*,*,*,組打ち,クミウチ,クミウチ 畿内,1285,1285,5770,名詞,一般,*,*,*,*,畿内,キナイ,キナイ
| 順番 | 内容 | 記述例 | 説明 |
|---|---|---|---|
| 1 | 表層形(形態素) | 似顔絵 | 辞書に登録したい単語 |
| 2 | 左文脈ID | 空白 | 意味は不明だが、空白にすると自動連番される。 |
| 3 | 右文脈ID | 空白 | 意味は不明だが、空白にすると自動連番される。 |
| 4 | コスト | 10 | 出現頻度を示す数値。 小さいほど出現頻度が高いとみなされる。 似たような単語が合った場合の優先順位として使われるようだが、適当な値(10とか)で問題無し |
| 5 | 品詞 | 名詞 | 品詞で何か判定する必要があれば「動詞」「名詞」「形容詞」など。 特に必要なければ「名詞」でOK。 |
| 6 | 品詞細分類1 | 一般 | 省略する場合は*を指定する。 |
| 7 | 品詞細分類2 | * | 省略する場合は*を指定する。 |
| 8 | 品詞細分類3 | * | 省略する場合は*を指定する。 |
| 9 | 活用型 | * | 省略する場合は*を指定する。 |
| 10 | 活用形 | * | 省略する場合は*を指定する。 |
| 11 | 原形 | 独自辞書 | 何らかの文字を記述しておかないとエラーで辞書が作成できない |
| 12 | 読み | 空白 | 省略する場合は空白にする |
| 13 | 発音 | 空白 | 省略する場合は空白にする |
上記のルールでCSVを作成し、mecab-dict-index.exe を使ってバイナリ形式に変換します。
mecab-dict-index -d システム辞書フォルダ -u 辞書のフルパス -f utf-8 -t utf-8 CSVのフルパス
例えば、MeCabのシステム辞書フォルダが ‘C:\Program Files\MeCab\dic\ipadic’ で、Dドライブの直下にある mydic.csv を、システム辞書フォルダと同じ場所に mydic.dic という名前で作成する場合は次の様になります。
"C:\Program Files\MeCab\bin\mecab-dict-index" -d "C:\Program Files\MeCab\dic\ipadic" -u "C:\Program Files\MeCab\dic\ipadic\mydic.dic" –f utf-8 -t utf-8 "D:\mydic.csv
文字コードはUTF-8にしていますが、もしユーザー辞書のCSVをEXCELで作成する場合は必然的に shift-jis で保存されますので、 -f shift-jis と記述して下さい。
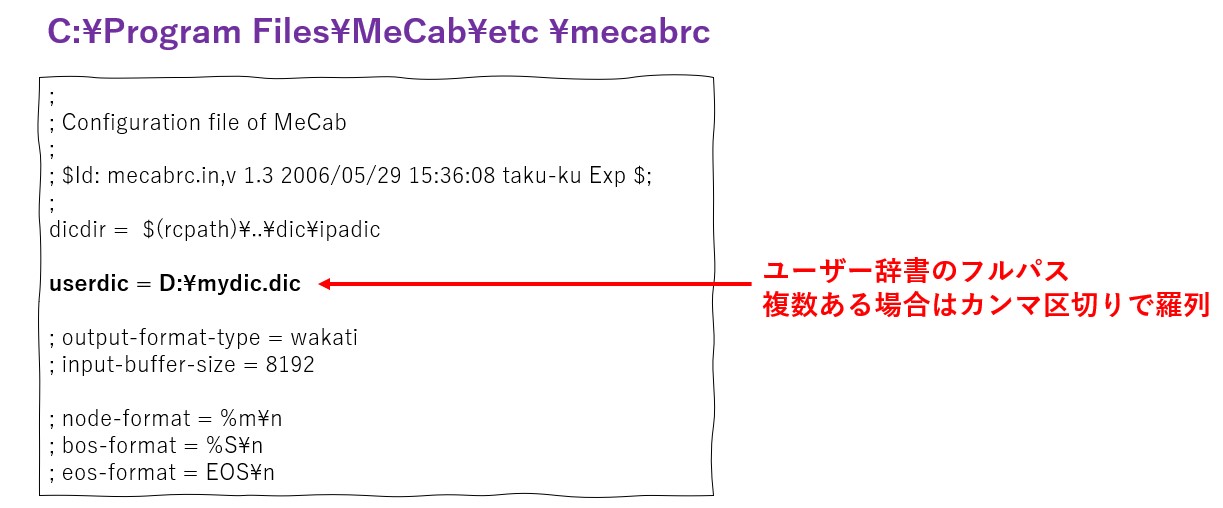
最後に、もしコマンドプロンプトでMeCabを利用する場合、C:\Program Files\MeCab\etc 直下にある mecabrc ファイルに対して、以下の要領でフルパスを指定すると、コマンドラインの MeCab でユーザー辞書が使えるようになります。
まとめ
今回は Windows上のPythonにおいて、64bit版のMecab を使うためのインストール方法と、MeCabを使った形態素解析の方法、ユーザー辞書の登録と使用について解説しました。
MeCabは形態素解析の老舗的存在であり様々な自然言語処理で利用されていますが、ネットにころがっているサンプルソースを実行してもMeCabがエラーとなり実行できないことがしばしばありました。
今回は、これらを整理する目的でAnaconda3-2021.11-Windows-x86_64.exe をゼロからインストールし、検証を行っています。
もし皆さんがMeCabのエラーに直面したら、この記事を思い出してもう一度チャレンジして頂ければと思います。
この記事が皆様のプログラミングのお役に立てれば幸いです。